
In this blog post I'm going to detail how deploy and configure a Nvidia GPU enabled Tanzu Kubernetes Grid cluster in AWS. The method will be similar for Azure, for vSphere there are a number of additional steps to prepare the system. I'm going to essentially follow the official documentation, then run some of the Nvidia tests. Like always, it's good to get a visual reference and such for these kinds of deployments.
Pre-Reqs
- Nvidia today only support Ubuntu deployed images in relation to a TKG deployment
- For this blog I've already deployed my TKG Management cluster in AWS
Deploy a GPU enabled workload cluster
It's simple, just deploy a workload cluster that for the compute plane nodes (workers) that uses a GPU enabled instance.
You can create a new cluster YAML file from scratch, or clone one of your existing located in:
~/.config/tanzu/tkg/clusterconfigs
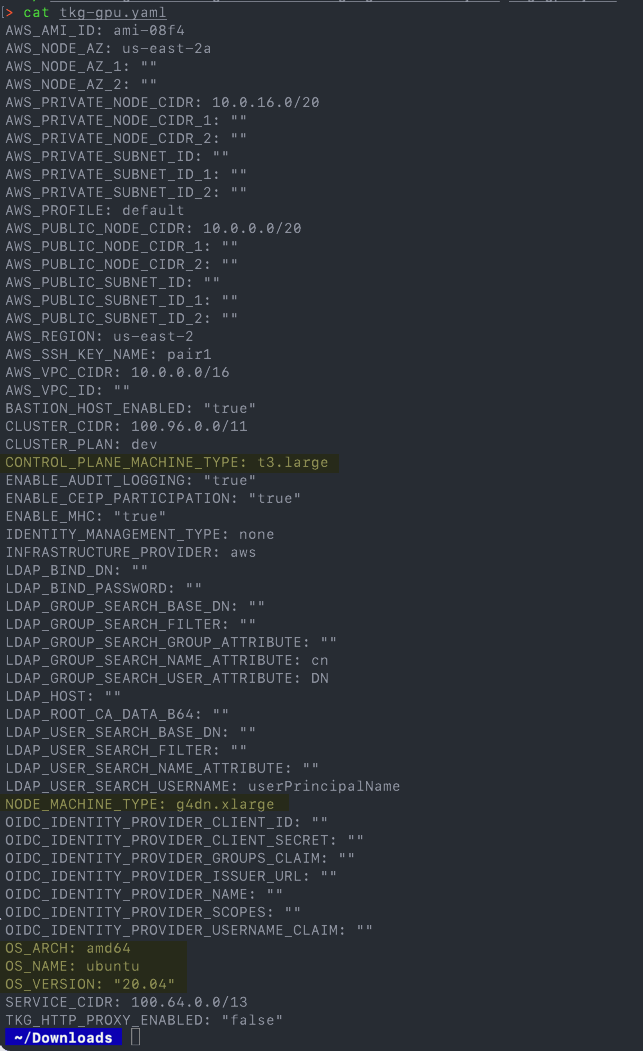
Below are the four main values you will need to change. As mentioned above, you need a GPU enabled instance, and for the OS to be Ubuntu. The OS version will default if not set to 20.04.
CONTROL_PLANE_MACHINE_TYPE: t3.large NODE_MACHINE_TYPE: g4dn.xlarge OS_ARCH: amd64 OS_NAME: ubuntu OS_VERSION: "20.04
The rest of the file you configure as you would for any workload cluster deployment.
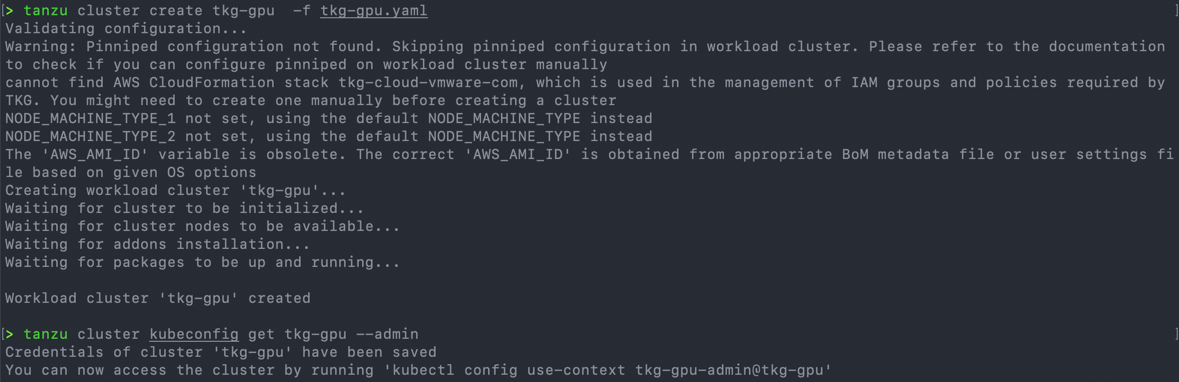
Create the cluster.
tanzu cluster create {name} -f {cluster.yaml}
You can retrieve the kubeadmin file to login by running.
tanzu cluster kubeconfig get {cluster_name} --admin
Deploying the Nvidia Kubernetes Operator
- Change the kubectl context to your newly deployed cluster.
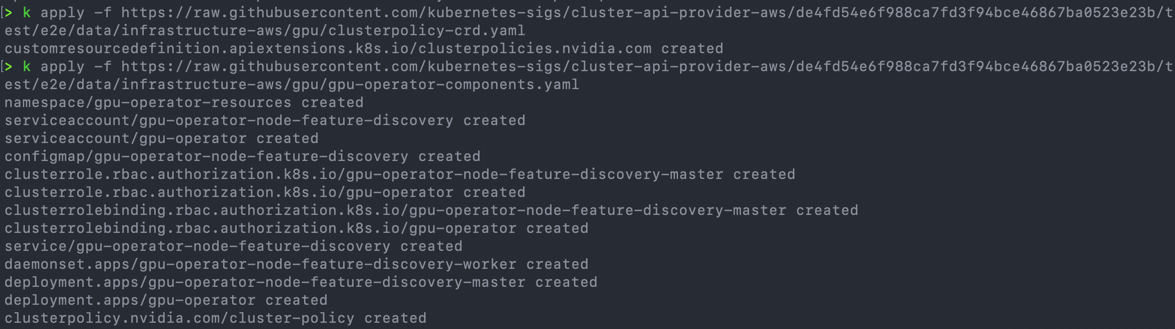
Deploying the Nvidia operator couldn't be easier, you can either download the files from the Cluster API for AWS github repo, or directly install them.
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/cluster-api-provider-aws/de4fd54e6f988ca7fd3f94bce46867ba0523e23b/test/e2e/data/infrastructure-aws/gpu/clusterpolicy-crd.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/cluster-api-provider-aws/de4fd54e6f988ca7fd3f94bce46867ba0523e23b/test/e2e/data/infrastructure-aws/gpu/gpu-operator-components.yaml
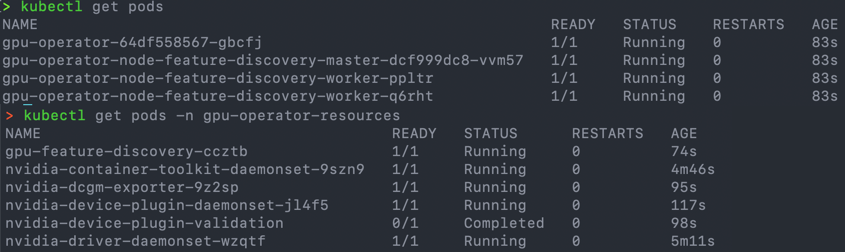
Validate the installation
Validate the operator pods in the default namespace, and then "nvidia" pods in the namespace "gpu-operator-resources".
kubectl get pods kubectl get pods -n gpu-operator-resources
If you scale out your cluster with additional nodes, the Nvidia operator will ensure the additional pods run on the new nodes.
Running the Sample Applications
From here to further validate, I am running the sample applications from the Nvidia documentation.
So rather than copy the exact configs here, I'm just showing the outputs.
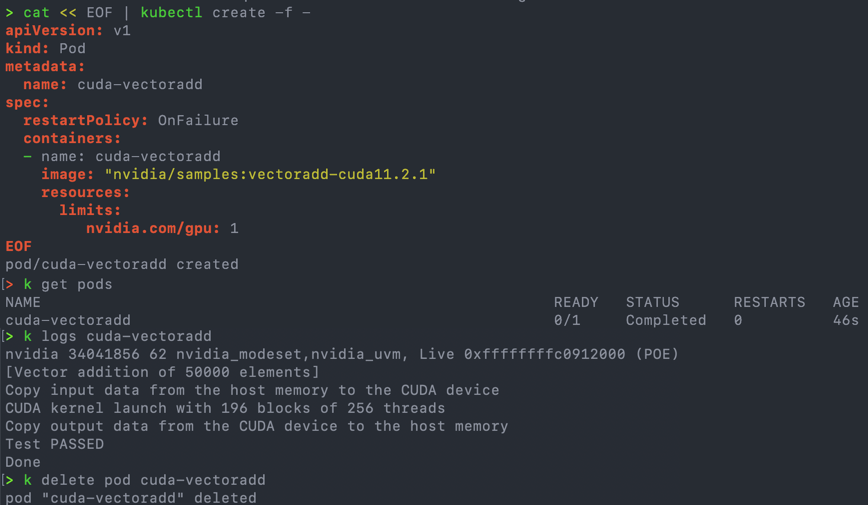
- CUDA VectorAdd
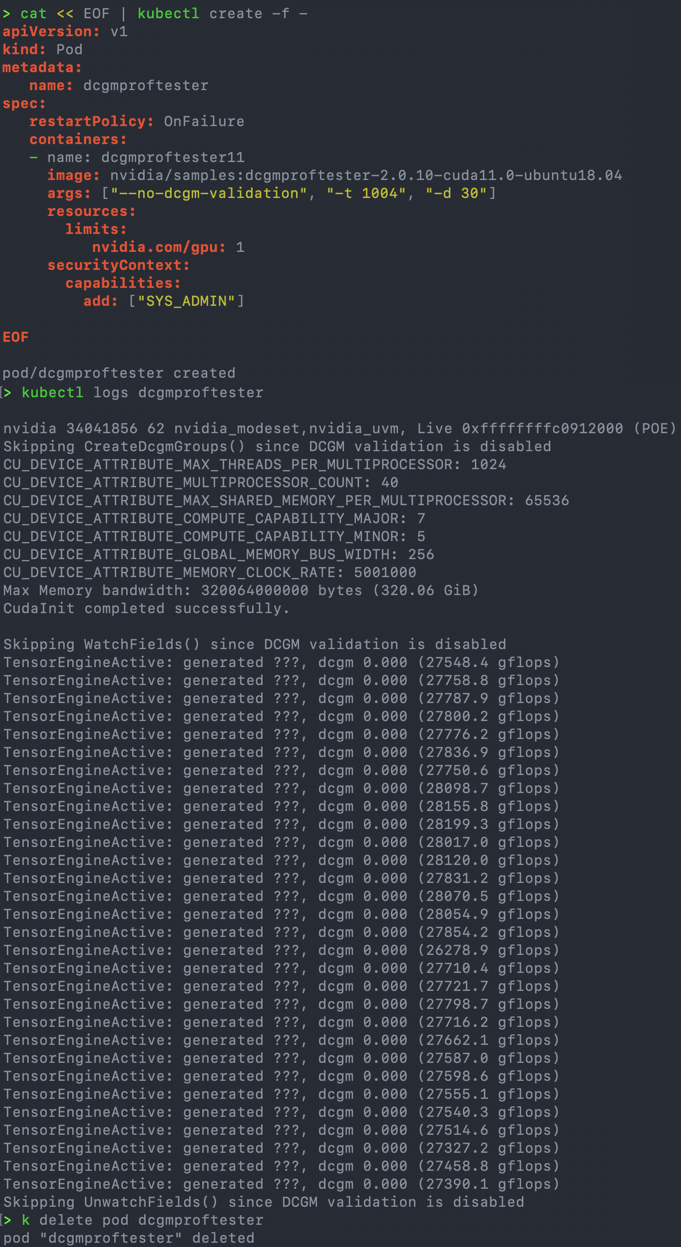
- CUDA load generator
If you want to look at further examples, Nvidia have some fantastic Deep Learning examples in this repository.
Wrap-up and Resources
Hopefully you can see that to use the GPU support with a Tanzu Kubernetes Grid cluster is quick and simple to setup and consume.
- Blog - VMware Tanzu Kubernetes Grid Now Supports GPUs Across Clouds
- Documentation
Regards