
Last exam of the year
The past few months I’ve forced my head into revision for the three CCNP exams, with two down, I have TSHOOT left to do, and I’m aiming to pass before Christmas Day. Which is a nice goal to have, but when I have to recertify next year, It’ll be around 24th December.
But currently, Cisco only requires you to pass one of the three exams to keep the CCNP.
The TSHOOT is an interesting exam, compared with others. It contains a small number of multiple answer based questions, however the bulk of the exam is sat around a pre-defined and publicly available topology, where within a simulator you troubleshoot various support tickets.

There’s even an online mock exam provided by Cisco, so you can get use to the way the simulator works before you sit the exam. To me, it’s very close to an open book exam, however having a busy work schedule, and a small amount of time to complete the exams, I personally will not have that much time to sit down and understand the topology inside out. So fingers crossed.
Using the TSHOOT study guide for something else
The first two chapters of the TSHOOT official study guide are actually a really good blueprint for infrastructure maintenance and troubleshooting which can be applied beyond that of just networking.
So that’s what I’m going to touch upon in this blog post.
Let’s start off with infrastructure maintenance, so this not only includes your network devices, but server and client hardware, the following are a few instances;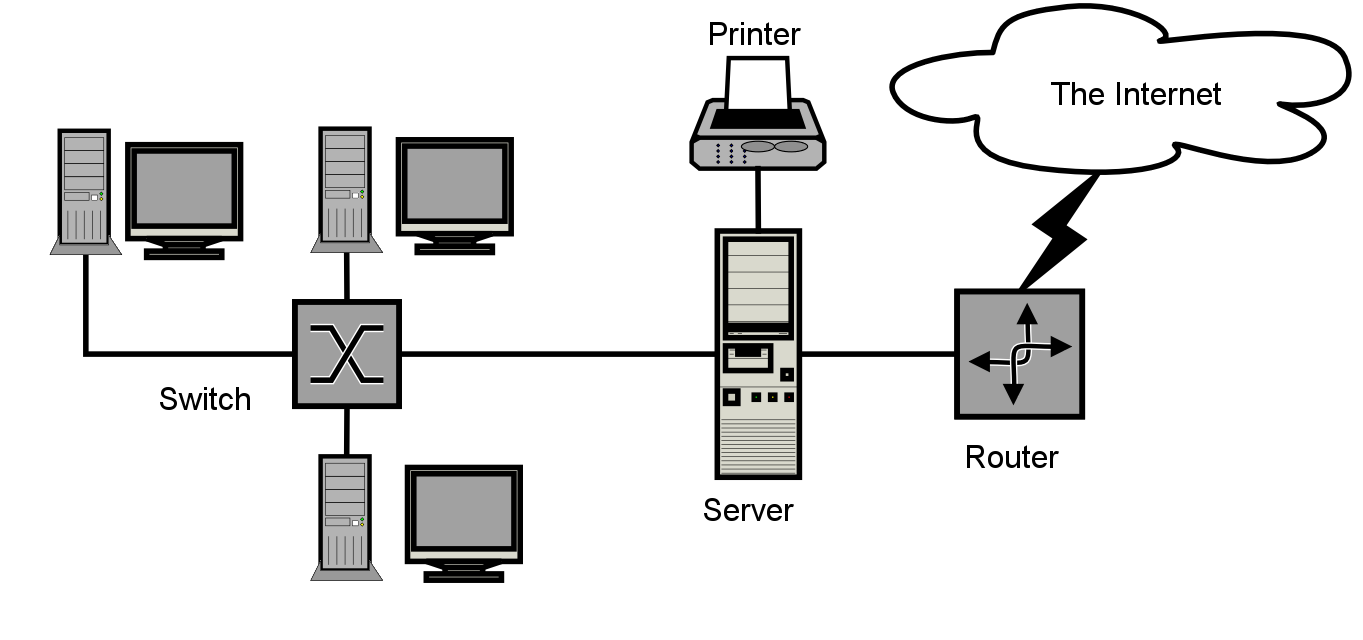
- Installation, provision and configuration of Hardware and Software
- Troubleshooting support incidents
- Monitoring applications and devices
- Optimizing applications and devices based on the monitoring
- Planning for future projects
- Scaling infrastructure
- Introducing new systems
- Replacement of hardware
- Documentation of infrastructure
- Ongoing updates to documentation as infrastructure changes
The above tasks can be undertaken in either a re-active format, or pro-active format. I don’t need to tell you that the proactive approach is the best way, but the reactive approach is the most travelled path.
Structure your ongoing tasks
Creating a structure is the best way to achieve a proactive approach to the above tasks. There are models to do this, which I urge you to investigate yourselves, rather than creating the wheel again from scratch, below are two of the most popular;
- FCAPS – Fault management, Configuration management, Accounting management, Performance management, Security management.
- ITIL – IT infrastructure library
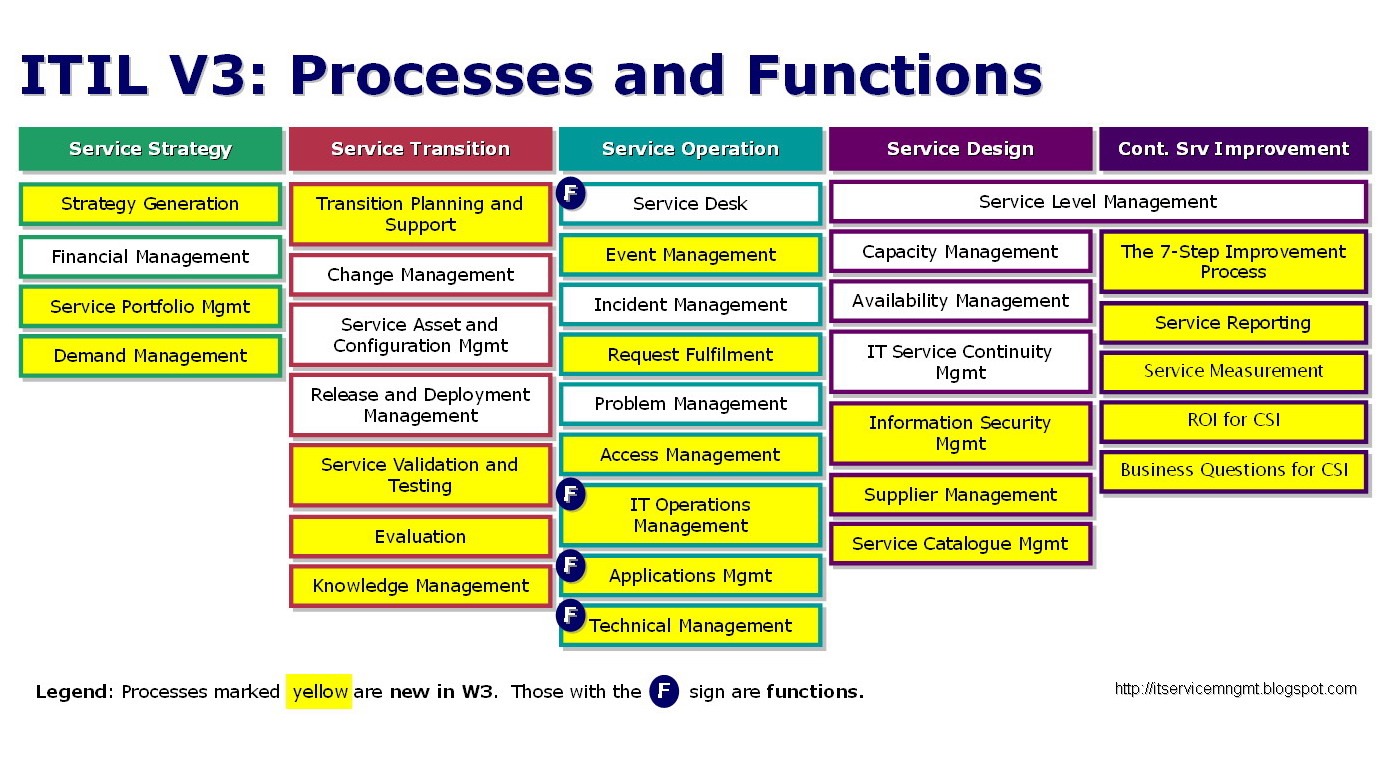
What you will find in your investigations is that neither model will really fit the company’s way of working, and implementing the above to the exact detail listed, could hamper the business instead of aiding the agility of the business. This is common, so my advice is to learn from both of the above, and the others out there, and take the best bits from them to implement your structure.
To do this, you also need to understand the way in which the business works, as well as the IT department. Especially the maintenance tasks undertaken, such as;
- Backup schedules of servers and data
- How configuration changes are conducted
- As needed
- Authorized after a change management request
- Hardware replacement strategy
- Firmware, Application and Operation System updates
- Ongoing monitoring of the Servers and other devices
The above tasks will have an importance marker in your head, such as backups been the most critical task to be performed. After these tasks have been defined, your overall structure will take place as you define who is responsible, and the actions that need to be taken under certain circumstances, such as 3 failed backups of the file servers must be escalated to third line support with a resolution time set to before the end of the day.
Documentation
One of the biggest parts of this structure will be the documentation, of which comes in two parts;
- Documentation of the standard operating procedures – these are the common critical tasks mentioned above
- Documentation of the infrastructure – Physical and logical diagrams, Inventories of hardware and software, Spreadsheets of IP address tracking
From these core documents, there will be off shoots, which include project and system documentation, focusing on the setup of particular systems, whether this be your Exchange Mail server setup, or the bespoke Just-in-time ordering system.
In your standard operating procedures, you will include some less visited functions such as disaster recovery processes, but also expand on the day to day tasks, providing troubleshooting documentation for common issues. In my previous employment, we used to run Online Exam software, which was notorious for failing to run for no obvious reasons, usually a registry key change would fix the issue. Therefore I wrote a document explaining how to troubleshoot the software not running, and the fixes.
Finally, at my last place of work, we had a document which listed all the external support contacts for any software, along with; any customer codes; ID numbers; serial numbers needed to raise a support ticket. And a further bit of information was the SLA level we should expect to receive, so any engineer on the team knew that when Software package A broke, if they logged a ticket with the developer they should receive a call back within X amount of hours.

All critical documentation should be subject to spot checks on a recurring schedule to ensure it is still up-to-date and accurate. Printed copies should also be kept in the case of a disaster recovery event, meaning the engineers working on the system have them to hand immediately. It’s all good keeping multiple electronic copies, but various issues can mean may not have an opportunity to access them.
The approach to troubleshooting
Looking in particular to the Cisco way of things, I think they hit the nail on the head in the study guide for the CCNP TSHOOT exam. They simplify the process into the following;
- Problem is reported
- Problem is diagnosed
- Problem is diagnosed
This is mimicked in the way the TSHOOT exam simulator’s run, funny how it all ties in together.
So how do we diagnose the issue? Cisco have a structured way of doing this;
- Problem is reported
- Engineer collects information about the problem
- Engineer examines the information
- Engineer eliminates Potential causes
- Engineer theorises on the underlying cause
- Verify theory by resolving the issue
If step 6 fails, return to step 4 and try again.
In the real world, some of these steps mix in with one another, as a human, we will try to evaluate the information we collect about the problem, rather than the above extrapolated tasks.
The method of troubleshooting, I’m sure we have all come across before, but for me, I think we all mentally know what they are, and the pros and cons of which is the correct approach. But each support incident comes with its own hybrid need of troubleshooting, meaning you change your approach on the fly, this will be based on your gut instinct and previous experiences.
Summary
A lot of the above will be in place, especially for larger companies, however everyone needs a refresher, and for smaller or new companies, the above may have never been considered or implemented.
Whilst revising for my upcoming exam, I can immediately see how chapters of the study guide can be adapted to my everyday working life. It also fits in nicely with a subject I’ve been blogging about recently, which is that of how to produce good documentation.
For me this blog post is about taking a step back, going to the basics, and revisiting a subject which we all know we should undertake day to day, but sometimes don’t.
Regards