
So basically I had a customer hit by a known HP-AMS driver issue (KB2085618), the symptons were as follows;
- Unable to vMotion a VM to another host, gives "operation timed out error"
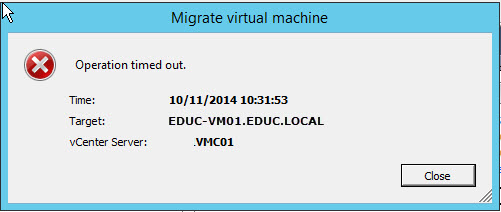
- If power off VM, vMotion a machine to another host, and then power on, you get the following error "Could not start VMX: msg.vmk.status.VMK_NO_MEMORY"
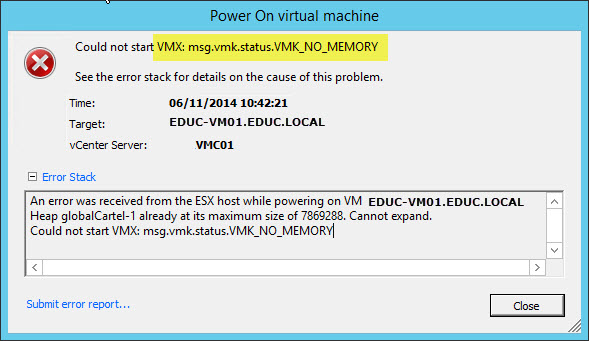
ESXi memory leak
This issue is caused by a memory leak in the driver which fills the SWAP memory of the ESXi host, making it unable to response to any requests at all,
For example, trying to enable SSH;
The Fix
So basically here's the fix, update to the latest HP-AMS Driver. However you will find just importing this into Update Manager, and trying to update a host will fail, because you can't migrate your machines, but if you turn them off, it still fails with an "Error 99" message which if you google, will point you here after reading a community post KB2043170.
Just reboot the host, after powering off your machines, as you will find if you log into the ESXi console directly (Remote iLO/iDRAC or Physically).
/bin/sh: can't fork

So the host is completely locked up.
After one host has rebooted, update with the latest patches, then vMotion your machines onto this host, bring them up, update your other hosts.
A technically simple fix, but a pain in the backside if you're hit with the issue once the memory leak has caused its damage.
Regards
On hosts that we've seen with the issue, there is no swap being used. I don't think swap is totally being consumed here, but haven't found the metric which one can watch to estimate when the issue will hit.
I understand where you are coming from, unfortunately once this issue hits, you lose control of the ESXi host.
I would simply advise to avoid this issue, update your HP-AMS driver to the latest version which fixes the issue.
Or remove it completely from the host, however you will lose come management of the HP system.
Therefore I would advise you to update it.
If you're like me and ran into this by the time it seemed too late, read on. Maybe you're even managing ESX remotely, your backups are failing and you can't really afford to shutdown all VMs to reboot ESX? Can't fork anything to accomplish it though? Do this:
(Prerequisite) PowerCLI needs to be up and running already (since it's already forked).
PowerCLI up to the host with Connect-VIServer
$ESXCLI = Get-EsxCli -VMHost yourhost
$esxcli.system.process.list() > C:\wtf.txt
search that file for ams. Jot the ID number down.
Shut down a VM and console in (i have ilo installed. Wasn't able to login on the console until I shut down one VM. perhaps it made JUST enough room to fork a shell?).
kill will work.
hurry up and issue these two in quick succession:
kill -9 IDnumberyoujotteddown
and then
/etc/init.d/hp-ams.sh stop - before it has a chance to come back.
Profit. Remove Service. Whatever.
I just wiggled out of this problem on a production box without rebooting doing the above.
Hi
Cheers for sharing that, it would seem you were very lucky, when I come across this, shutting down VMs did not allow me to do anything with the host still.
Im not sure how many people will have an existing session via PowerCLI, however its always good to know there is other options to explore first
Once again, cheers for sharing
Yeah, I think I hit it fast enough for there to be enough "room" for a shell to spawn. I couldn't do a second instance of a shell nor run anything in it. kill doesn't need to fork so as long as you are in a shell, you can run it.
I guess I lucked out on the PowerCLI front. My backup software uses a PowerCLI proxy to do its thing, so I had it running.
This has saved me from some serious headache! Thanks a bunch!!
Like you said, you have to be fast! Took me three tries to get this to work. :)
thank you for the feedback!