
Updated 29.01.15 - Please see this new post for the patch fix
So on twitter I found out that VMware CBT has a bit of a fault, the tweet linked me to reddit here.
Basically CBT has a fault where if you are using CBT on a VMDK file thats <128GB, and then increase this file >128GB, still using CBT. The query used to process the data blocks in use may return the wrong value, meaning your backups are corrupt, because they have backed up the wrong files.
Heres the official VMware KB2090639.
Heres Veeam's KB1940 (Now includes hotfix).
Finally the Symantec KB <<< Now down due to been changed to a tech note from a KB????
Quick Summary of issue
Basically if your disk is below 128GB, your fine,
If you disk is extended over 128GB, you might suffer the issue.
If your disk is over 128GB, you should be fine, unless you extended it over 128GB, then you may not be fine.
Are virtual machines grown in smaller increments affected?
The amount of space the virtual disk is extended is not relevant, the increment of space by which a virtual disk is extended is not relevant.
Virtual machine is affected when the disk is grown past the 128G boundary in absolute size. The issue is triggered at other sizes which are a power of 2 from 128G up. For example: 256G, 512G, and 1024G.
The other spanner in the works is basically VMware say if you do match the above criteria, you still may not experience the issue, there is someone on the reddit forums who has suffered this issue for 2 years, and VMware nor Veeam have found a fix.
It would seem that this issue affects VMDK's when you go past any 128GB boundary, scroll down to the Symantec statement for more information.
On the Reddit post, users have contacted VMware for a clarification of the issue;
Just had this in from VMware support "Yes the vmdk which is extended by 20 GB ten times will be affected with this issue as the expansion of disk is more than 128 GB when added together."
Also to add that just because a VMDK has had extensions which mean that it is affected VMware said it doesn't necessarily mean it will be affected - so you wouldn't be able to reproduce this error 100% of the time.
So how wide spread is this issue?
Well it depends on your Backup Software, if you've changed a VMDK file size from below 128GB to over that, and how long your retention period is, and the software you use.
If your backup software is agent based, it is probably unaffected, as it will pull information from the Guest OS. Where as non agent based, if using VADP, will be affected. Either way, check with your Software Vendor.
If you're using Veeam SureBackup feature, this can do a consistency check on your backups, and if everything passes, then you should have any issues. (I'm planning on writing a quick blog on how to set up this kind of Job.)
Solution
Always run a Full Active Backup after making any changes!!!!
Solution 1 - offered by Veeam:
Go to this KB1940.
Apply the following hotfix to protect your backups. 1. Make sure you are running Veeam Backup and Replication 7.0.0.871 (patch 4) otherwise obtain a patch vee.am/kb1891 2. Stop all Veeam services 3. Replace DLL's in C:\Program Files\Veeam\Backup and Replication\Backup 4. Start Veeam services Veeam Backup and Replication 8 has a built-in solution for this issue.
The above hotfix essentially performs the below manual steps, which Veeam released as a workaround upon discovering the issue.
Reset CBT on all your backed up VM's, by disabling it, and letting Veeam re-enable it automatically when it backups up a machine. Obviously this will add overhead on your backup processing and time taken to complete the backup.
You can do this using PowerCLI, which I found from VMware's KB2075984 here, you need to change the highlighted text to $False
Get-VM | Get-View | foreach {
$spec = New-Object VMware.Vim.VirtualMachineConfigSpec
$spec.changeTrackingEnabled = $true
$taskMoRef = $_.ReconfigVM_Task($spec)
}
I'm not sure if other backup products will work with the same workaround, you will need to consult the documentation.
There is a secondary script posted in the Veeam communities link below, which disables CBT and then creates and removes a snapshot, which commits the changes
$vms=get-vm | ?{$_.ExtensionData.Config.ChangeTrackingEnabled -eq $true}
$spec = New-Object VMware.Vim.VirtualMachineConfigSpec
$spec.ChangeTrackingEnabled = $false
foreach($vm in $vms){
$vm.ExtensionData.ReconfigVM($spec)
$snap=$vm | New-Snapshot -Name 'Disable CBT'
$snap | Remove-Snapshot -confirm:$false}
As always, do your own testing first!!!
Solution 2 - offered by me
If possible, then you can also reset CBT by using Storage vMotion to another datastore. This obviously works if you have the space available, if not, then create a small partition big enough for one VM at a time, Storage vMotion to this temporary datastore, then move it back to its original location.
However VMware have KB2048201 that says pre 5.5u2, this may cause an issue with your backups. However Veeam recommend running a Active Full Backup after any changes, although their testing has shown it is not needed. Better safe than no backups eh?
So I contacted via Twitter, ArcServ, Symantec and Dell Appsure, for commends, below are from the vendors who have replied or released something;
Veeam statement
Heres the current statement from Veeam, which was included in a round-up email sent to customer, but can also be found on the Veeam Communities.
Unfortunately, I also have some not so good news to share. Earlier this month, VMware has quietly published a KB article about pretty terrible CBT bug that exists in all versions of ESX(i) since changed block tracking functionality was first introduced. We have been working directly with VMware to confirm the exact scope of the issue and update the KB article with more details. But the main point is that your backups and replicas for all VMs that had its virtual disk size expanded beyond 128 GB at some point may be unrecoverable. We are working on a hot fix for both 7.0 Patch 4 and 8.0 code branches that will reset CBT automatically upon detecting source virtual disk size change. Meanwhile, I recommend manual CBT reset for all VMs that had their virtual disks expanded at some point by disabling CBT (the following Veeam job run will re-enable CBT automatically). Perhaps, just disabling CBT on all VMs with a PowerCLI script might be the best idea - but keep in mind that the following job runs will take much longer, so best is to do this before the weekend. These kind of issues always make me stress the importance of SureBackup. Many users consider setting up SureBackup jobs to be a low priority when compared to actual backups - however, only SureBackup is able to catch these kind of issues. Interestingly enough, a lot of people seem to recognize the importance of backup integrity testing, in fact our Backup Validator tool seems to be very popular. I do agree that integrity checks are important, in fact I have dedicated the entire VeeamON breakout session to "classic" data corruption issues. However, integrity checks will not detect corruption issues similar to the above. And yet, these sort of issues are much more common. I cannot stress this enough, especially in light of enhancements we are adding to our Backup Validator tool in v8. These enhancements are based on your feedback, but they do not mean that Backup Validator is the future. It has its use in detecting storage level corruptions, but only SureBackup can guarantee you the ability to recover.
Symantec statement
So they got back to me on twitter and also emailed with the below;
This was from Elias AbuGhazaleh (Twitter Handle: @BE_Elias or @Backupexec)
The guys at BE have excelled theirselves in creating a dialog with me about the issue and providing information. So hats off to them.
Update 30/10/2014; I recieved the following update from Elias today;
In our internal testing we have concluded that CBT will ALWAYS be incorrect after extending a virtual disk past the 128GB boundary. The issue is not related to the QueryChangeDiskAreas() API call but rather the CBT info itself. As such, regardless if the QueryChangeDiskAreas is called with ‘*’ or a timestamp CBT will be incorrect. This does not result in data loss in all cases; it could be over-reporting of changed blocks as well. Symantec engineering is actively investigating ways we can mitigate the issue in our products (Backup Exec & NetBackup). As there is no way of detecting if a VM is affected, no backup product can be fully immune from this issue. The recommended course of action to take is to reset CBT for any VM that has a vmdk greater than 128GB.
Symantec now had an official KB225910 out, but its been pulled to changed into tech note apparently, and it would seem they have been doing a lot of testing, this is the most interesting part;
VMware Policies with Block Level Increment Backup enabled OR any VMware Policy backing up a virtual machine the has CBT enabled where the virtual disk (vmdk) has been resized to cross the following boundaries: 128GB, 256GB, 512GB, 1024GB. These are the boundaries we have discovered in internal testing to be affected and there may be additional boundaries affected. The root cause is the Changed Block Tracking information is getting corrupted when crossing these boundaries.
Finally, I shout out to Aaron Meza @aaronmeza for also conversing with me on/offline via twitter and Linkedin, he has helped me understand the situation better, and the efforts put in by Symantec to work with VMware in defining this issue and hopefully finding some sort of work around.
Dell Statement
I've been taking to Gina Minks @gminks (Product Marketing Manager for Dell AppAssure). Below is them confirming this issue doesnt affect them;
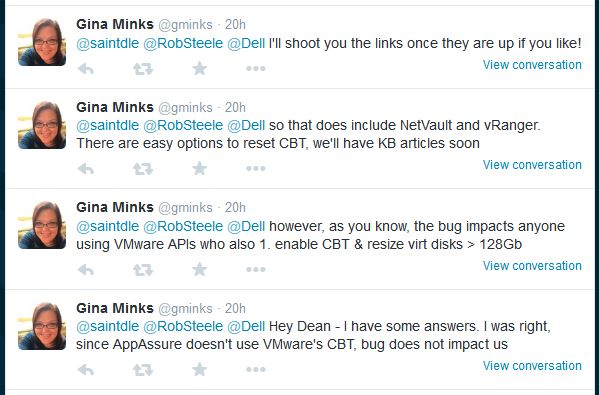
Regards
At the very least, you can slim down the number of machines you have to reset CBT on. Try:
?{$_.ProvisionedspaceGb -gt 128 -and $_.ExtensionData.Config.ChangeTrackingEnabled -eq $true}
Where in the script should this be added? what would be the syntax to just list the VMs?
Maybe try this one from Veeam
get-vm | ?{$_.ExtensionData.Config.ChangeTrackingEnabled -eq $true}