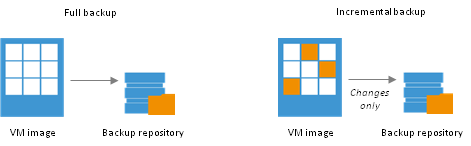
vSphere data loss bug returns - CBT issues in vSphere ESXI 8.0 update 2
The Issue I keep saying, there are no new ideas in technology, just re-hashes of old ones. That is also true for VMware and their data loss issues. The…
Read guide →5 vEducate articles tagged CBT.
The Issue I keep saying, there are no new ideas in technology, just re-hashes of old ones. That is also true for VMware and their data loss issues. The…
Read guide →Following on from the recent (November 2015) ESXi 6.0 CBT bug, which has now been fixed in the latest released patch ESXi600-201511401-BG, some further…
Read guide →I wrote about the latest CBT issue (November edition) a couple of days ago, and as promised by VMware a patch has been released. Original issue - KB 2136854…
Read guide →VMware have finally released a patch to fix the Major CBT bug that causes your backups to be corrupted because the changed blocks are reported incorrectly.…
Read guide →Updated 29.01.15 - Please see this new post for the patch fix So on twitter I found out that VMware CBT has a bit of a fault, the tweet linked me to reddit…
Read guide →