
In this blog post we will cover how to configure Red Hat OpenShift to forward logs from the ClusterLogging instance to an external 3rd party system, in this case, VMware vRealize Log Insight Cloud.
Architecture
The Openshift Cluster Logging will have to be configured for accessing the logs and forwarding to 3rd party logging tools. You can deploy the full suite;
- Visualization: Kibana
- Collection: FluentD
- Log Store: Elasticsearch
- Curation: Curator
However, to ship the logs to an external system, you will only need to configure the FluentD service.
To forward the logs from the internal trusted services, we will use the new Log Forwarding API, which is GA in OpenShift 4.6 and later (it was a tech preview in earlier releases, and the configuration YAMLs are slightly different, so read the relevant documentation version).
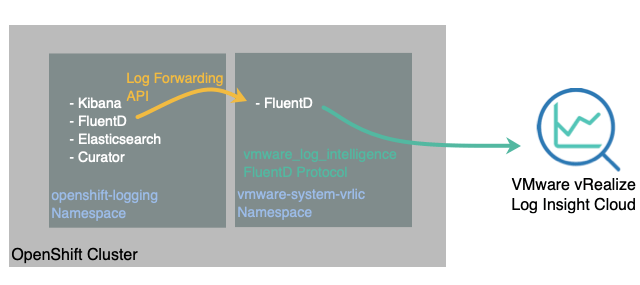
This setup will provide us the architecture below. We will deploy the trusted namespace "OpenShift-Logging" and use the Operator to provide a Log Forwarding API configuration which sends the logs to a 3rd party service.
For vRealize Log Insight Cloud, we will run a standalone FluentD instance inside of the cluster to forward to the cloud service.
The log types are one of the following:
application. Container logs generated by user applications running in the cluster, except infrastructure container applications.infrastructure. Container logs from pods that run in theopenshift*,kube*, ordefaultprojects and journal logs sourced from node file system.audit. Logs generated by the node audit system (auditd) and the audit logs from the Kubernetes API server and the OpenShift API server.
Prerequisites
- VMware vRealize Log Insight Cloud instance setup with Administrator access.
- Red Hat OpenShift Cluster deployed
- with outbound connectivity for containers
- Download this Github Repository for the configuration files
git clone https://github.com/saintdle/openshift_vrealize_loginsight_cloud.git
Deploy the standalone FluentD instance to forward logs to vRealize Log Insight Cloud
As per the above diagram, we'll create a namespace and deploy a FluentD service inside the cluster, this will handle the logs forwarded from the OpenShift Logging instance and send the to the Log Insight Cloud instance.
Creating a vRealize Log Insight Cloud API Key
First, we will create an API key for sending data to our cloud instance.
- Expand Configuration on the left-hand navigation pane
- Select "API Keys"
- Click the "New API Key" button
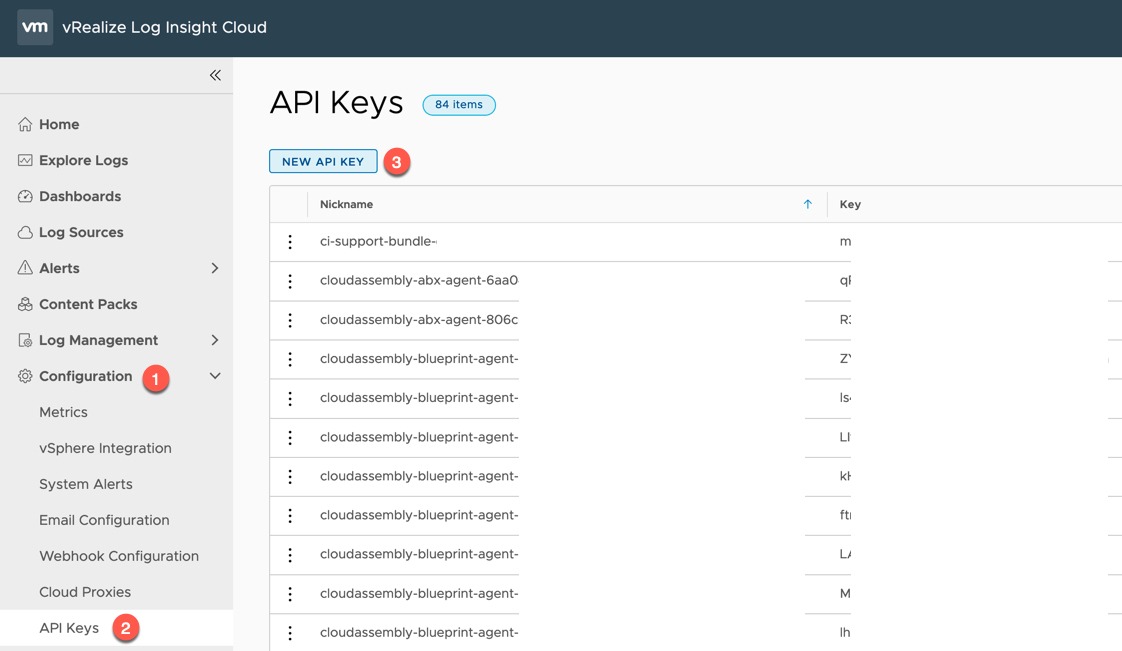
Give your API key a suitable name and click Create.

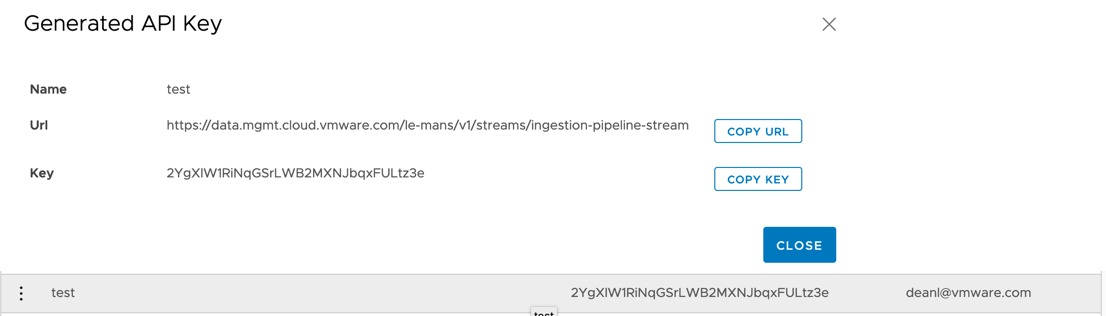
You will be given your API URL and Key in a dialog box, but you'll also be able to see the Key in the list as well.
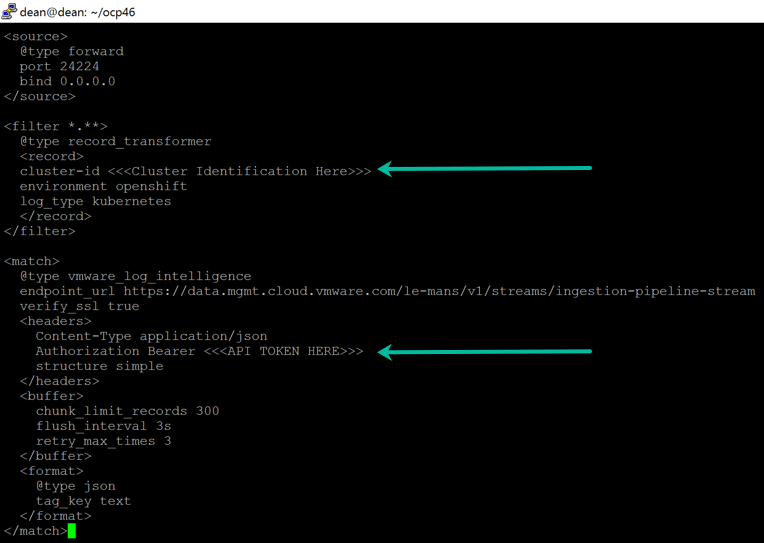
Move into your git repo folder from the per-requisites and edit the fluent.conf file to add in your API key.
At this point you'll also want to add in your Cluster-id, this can be a name for the cluster you chose, or you can get the OpenShift Cluster-id using the following command;
oc get clusterversion -o jsonpath='{.items[].spec.clusterID}{"\n"}'
Deploy FluentD standalone instance to the OpenShift Cluster
Log onto your OpenShift cluster via your terminal, and deploy the namespace;
oc apply -f openshift_vrealize_loginsight_cloud/01-vrli-fluentd-ns.yaml
This will create a namespace (a.k.a OpenShift project) called "vmware-system-vrlic"
Create a configmap for the FluentD Container Service to allow it to receive files from the Cluster Logging instance, and forward using the FluentD vmware_log_intelligence protocol.
oc create configmap vrlicloud-fluent-config --from-file=penshift_vrealize_loginsight_cloud/fluent.conf -n vmware-system-vrlic
Create the Fluentd Deployment.
oc create -f openshift_vrealize_loginsight_cloud/02-vrli-fluentd-deployment.yaml
Once deployed take a note of the Cluster-IP assigned to the deployment, we will use this in the Log Forwarding API configuration.
oc get svc -n vmware-system-vrlic
![]()
Installing and Configuring the ClusterLogging Instance
On your OpenShift cluster we need to configure the ClusterLogging instance which will deploy the services needed in a privileged namespace, where the services will have the correct security contexts to access the system.
In this blog we will continue the setup using the OpenShift Web Console, if you want to use the CLI still, please follow the OpenShift documentation.
In the Web Console, go to the OperatorHub page.
Filter by using the keyword "logging" and install both Cluster Logging Operator and the Elasticsearch Operator.
Note: the Elasticsearch operator needs to be installed even though we will not configure it due to dependencies.
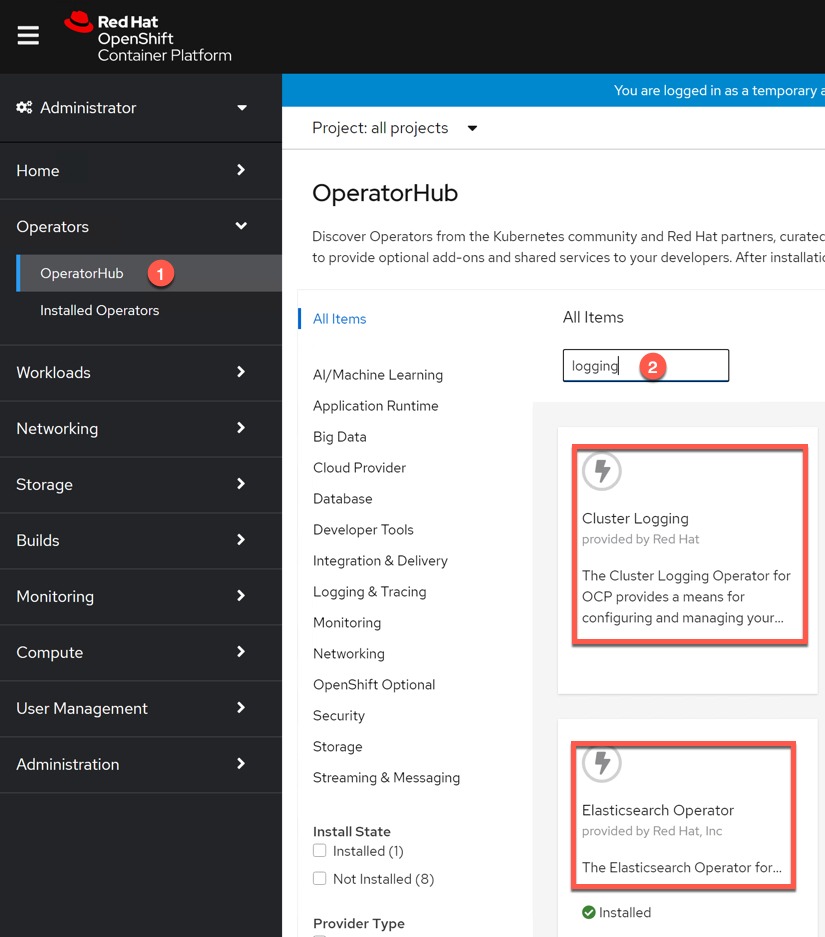
Install both using the default settings, this will create the privileged "Openshift-logging" namespace if it does not already exist.
Go to the Installed Operators page and click on "Cluster Logging" Operator.
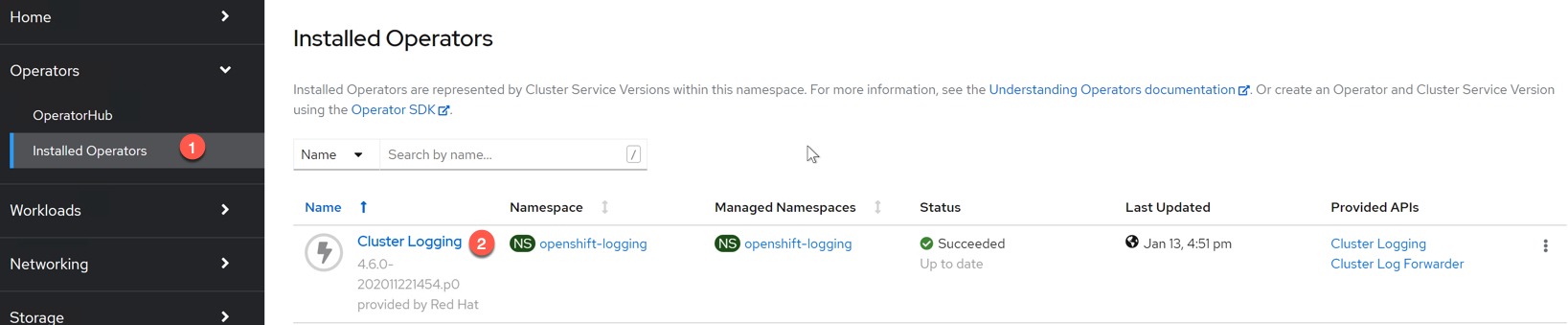
We will now create a Cluster Logging instance; in this blog post I will only deploy the FluentD and Curator services. But you can deploy a full monitoring suite as per the OpenShift documentation.
Click the Cluster Logging Tab, and then Create ClusterLogging blue button.
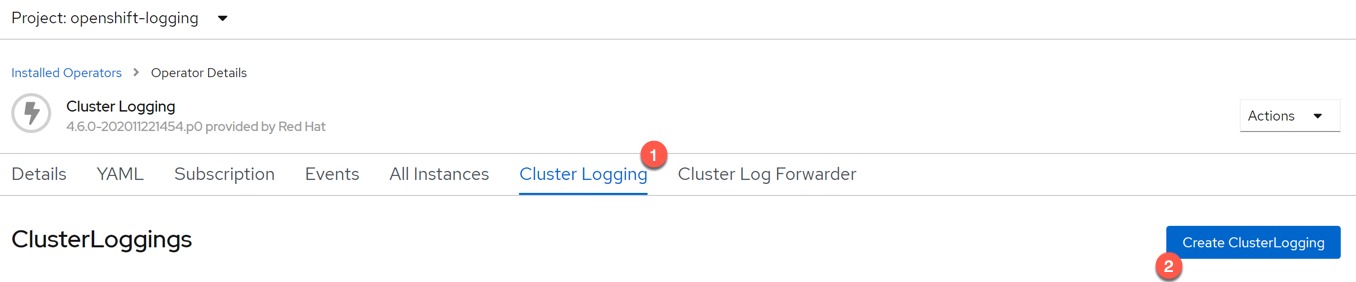
Change your view to YAML. And edit the YAML file to the below.
apiVersion: logging.openshift.io/v1
kind: ClusterLogging
metadata:
namespace: openshift-logging
name: instance
spec:
collection:
logs:
fluentd: {}
type: fluentd
managementState: Managed
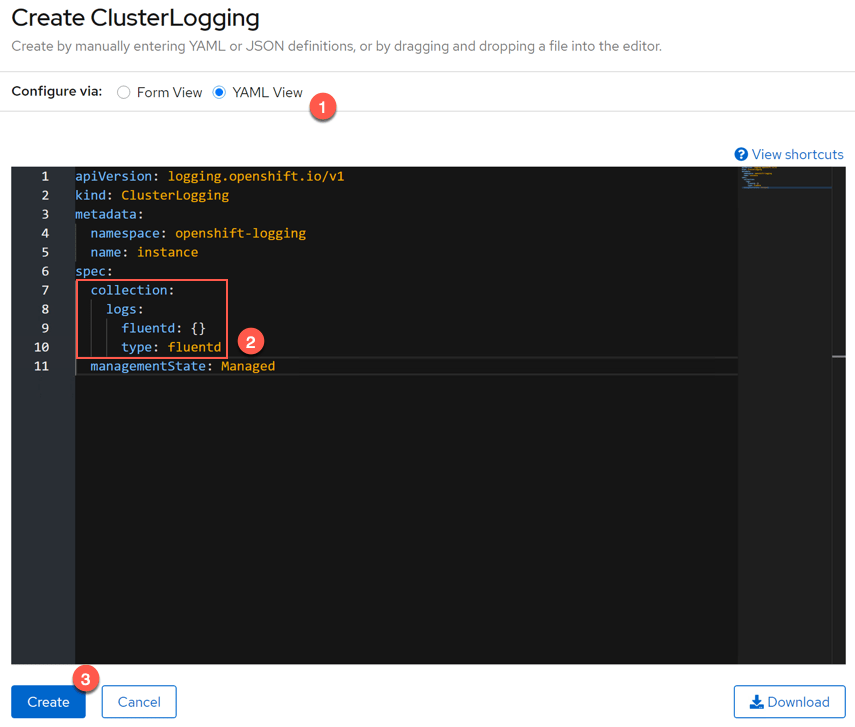
Click create, and this will deploy the FluentD pods.
Note: if you were looking to deploy the full Cluster Logging suite, you can use a YAML such as this example YAML;
apiVersion: "logging.openshift.io/v1"
kind: "ClusterLogging"
metadata:
name: "instance"
namespace: "openshift-logging"
spec:
managementState: "Managed"
logStore:
type: "elasticsearch"
retentionPolicy:
application:
maxAge: 1d
infra:
maxAge: 1d
audit:
maxAge: 1d
elasticsearch:
nodeCount: 3
requests:
cpu: "1"
memory: 4Gi
resources:
limits:
memory: 4Gi
storage:
size: 50G
storageClassName: csi-sc-vmc
redundancyPolicy: "SingleRedundancy"
visualization:
type: "kibana"
kibana:
replicas: 1
curation:
type: "curator"
curator:
schedule: "30 3 * * *"
collection:
logs:
type: "fluentd"
fluentd: {}
Create the Log Forwarding API configuration
On your Cluster Logging Operator Page, click the Cluster Log Forwarder Tab, then "Create ClusterLogForwarder" blue button.

Change to YAML view and provide the configuration as below, substituting your Cluster-IP of the Standalone FluentD deployment we created earlier;
apiVersion: logging.openshift.io/v1
kind: ClusterLogForwarder
metadata:
name: instance
namespace: openshift-logging
spec:
outputs:
- name: fluentd-server-insecure
type: fluentdForward
url: 'tcp://<CLUSTER-IP>:24224'
pipelines:
- inputRefs:
- application
- infrastructure
- audit
name: to-vrlic
outputRefs:
- fluentd-server-insecure
The spec is broken down into two sections. Your Output configuration, which is where you are going to send your logs. You are able to have multiples of these.
The second part is your Pipeline configuration, which has an input of which logs you are interested in forwarding (inputRefs), and which of the Output configurations will be used (outputRefs). You can find further examples within the OpenShift documentation here.
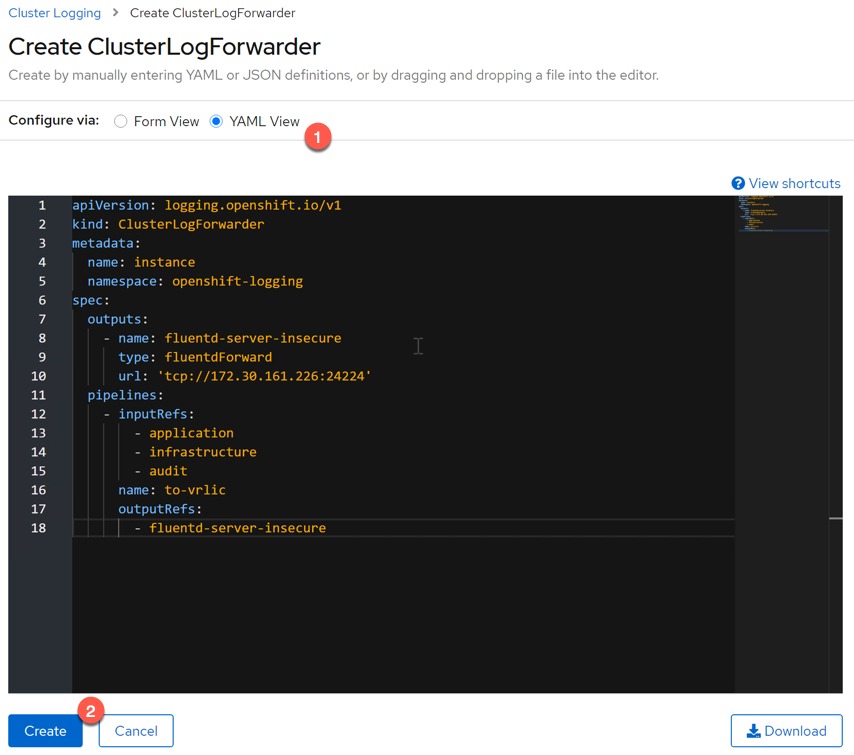
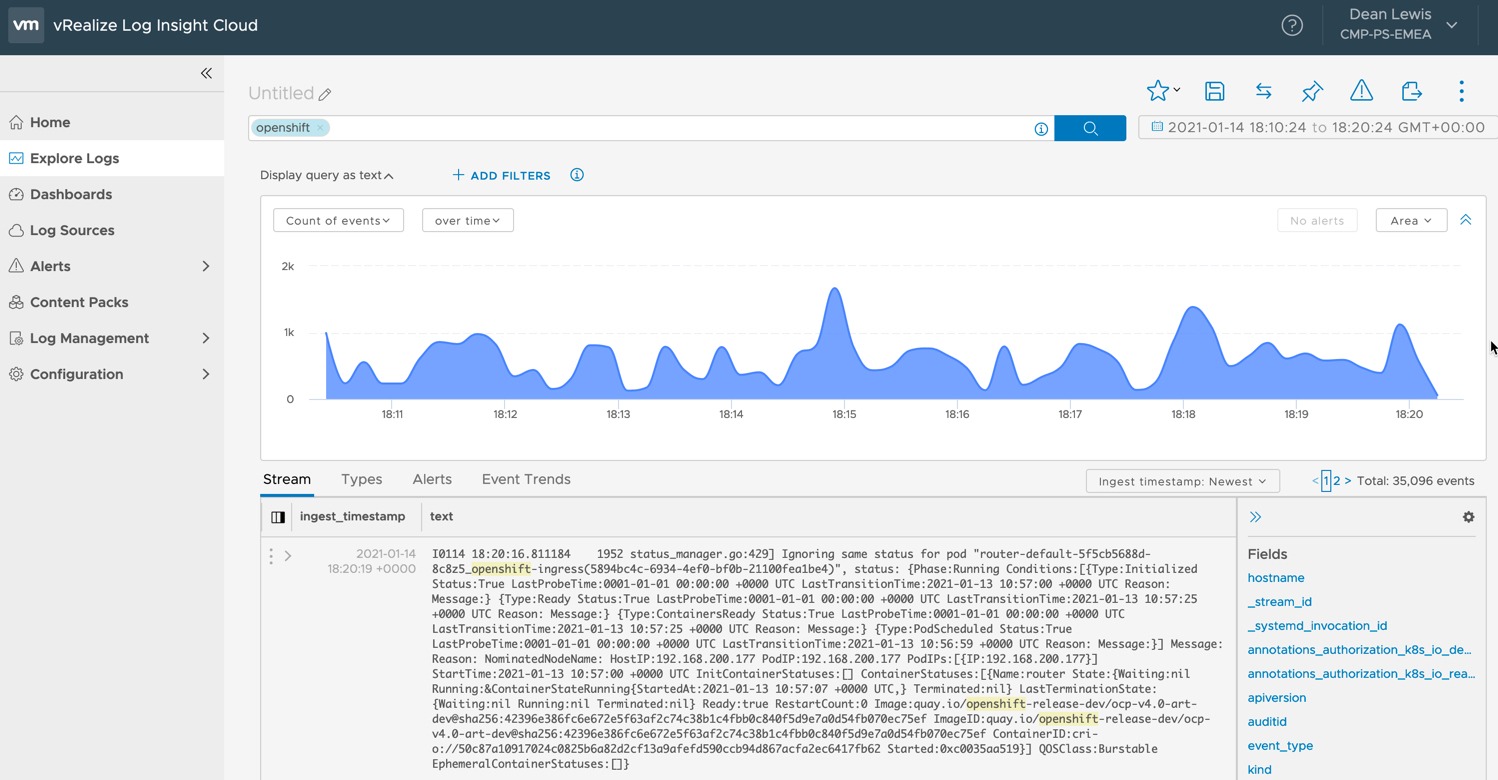
Click Create, and soon you should Logs from your OpenShift environment hitting your vRealize Log Insight Cloud Instance.
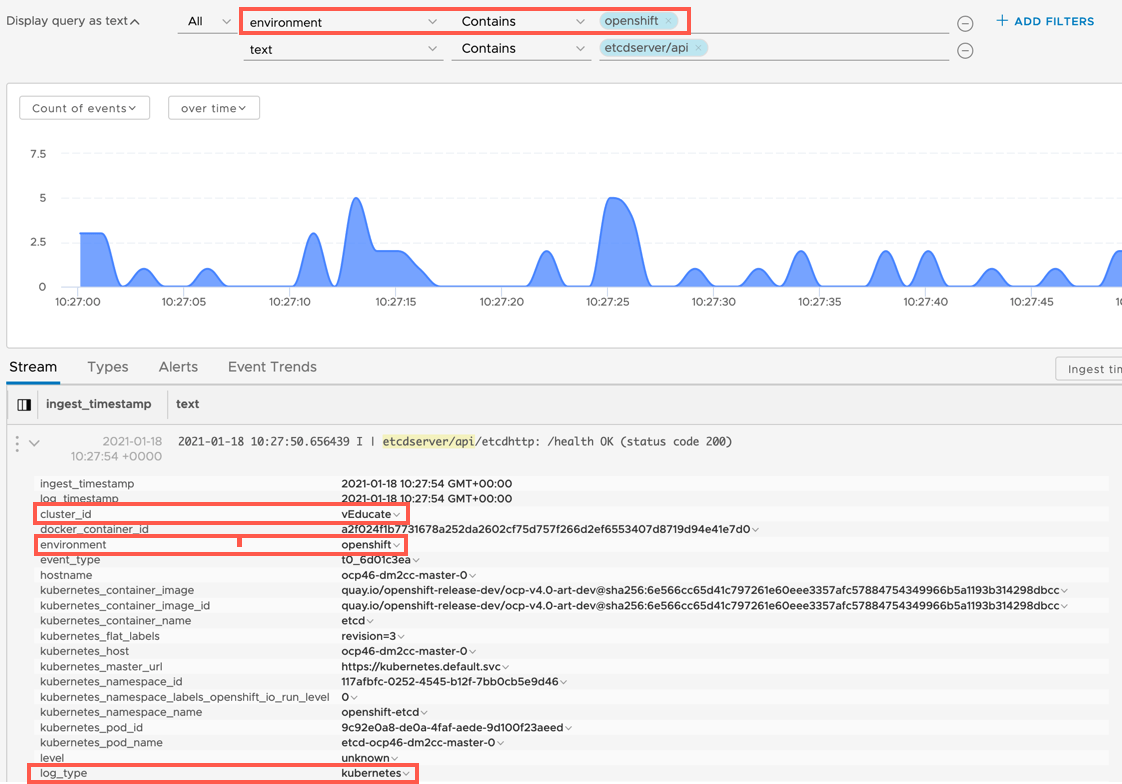
You can also filter the search by the filters set in your fluentd.conf file, below I've searched for environment type "openshift" but in the log, you can see my Cluster-id I've manually set, as well as the log-type being identified as Kubernetes.
If you want to take the monitoring of your Red Hat OpenShift Clusters further, VMware vROPs supports this Kubernetes implementation as an endpoint. You can follow my blog here, on how to get started;
Thank you to Munishpal Makhija at VMware, whom worked with me on this updated solution. You can view his blog post of the same subject here.
Regards