Note: Following Broadcom's acquisition of VMware in 2023, Tanzu Kubernetes Grid (TKG) and vSphere with Tanzu continue under the Broadcom portfolio. Licensing and support terms have changed significantly — consult current Broadcom documentation for the latest requirements before following this guide.
In this blog post I am going to walk you through how to edit the Machine Resource configurations for nodes deployed by Tanzu Kubernetes Grid.
Example Issue - Disk Pressure
In my environment, I found I needed to alter my node resources, as several Pods were getting the evicted status in my cluster.
By running a describe on the pod, I could see the failure message was due to the node condition DiskPressure.
- If you need to clean up a high number of pods across namespaces in your environment, see this blog post.
kubectl describe pod {name}
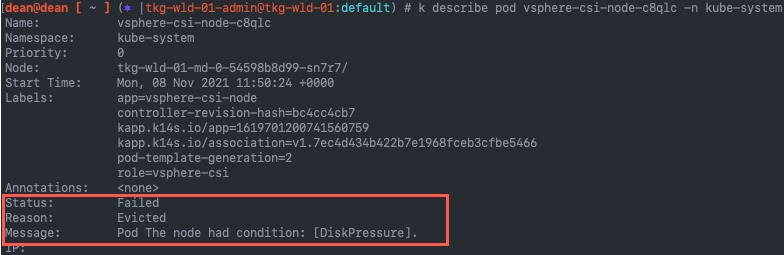
I then looked at the node that the pod was scheduled too. (You can see this in the above screenshot, 4th line "node").
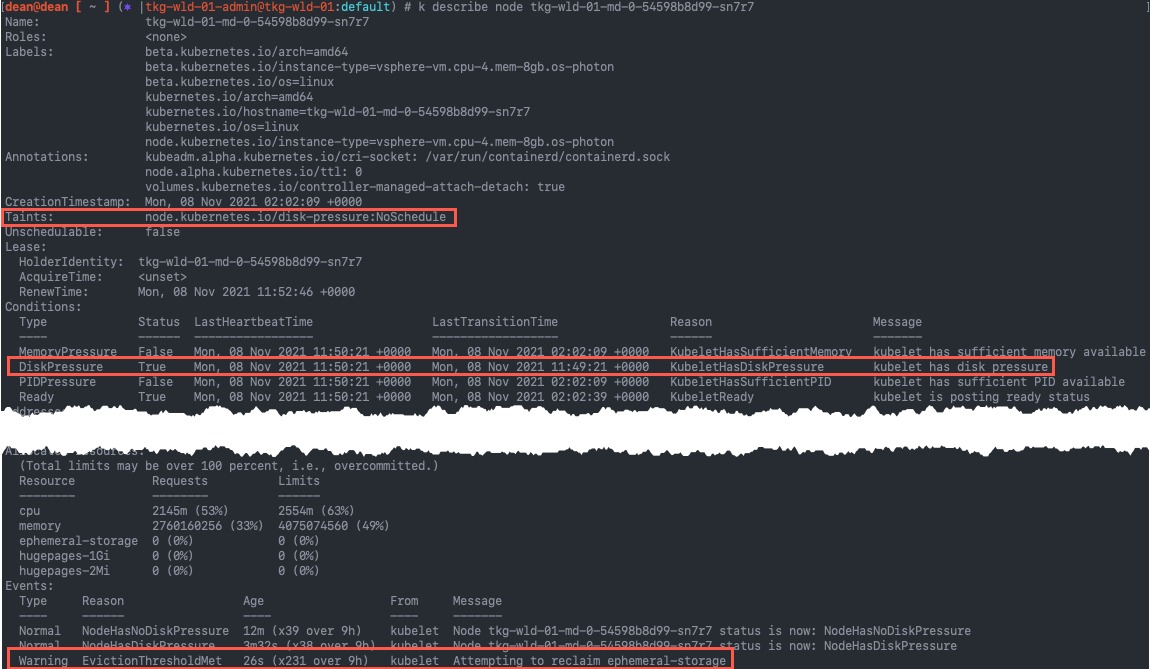
Below we can see that on the node, Kubelet has tainted the node to stop further pods from being scheduled to this node.
In the events we see the message "Attempting to reclaim ephemeral-storage"
Configuring resources for Tanzu Kubernetes Grid nodes
First you will need to log into your Tanzu Kubernetes Grid Management Cluster, that was used to deploy the Workload (Guest) cluster. As this controls cluster deployments and holds the necessary bootstrap and machine creation configuration.
Once logged in, locate the existing VsphereMachineTemplate for your chosen cluster. Each cluster will have two configurations (one for Control Plane nodes, one for Compute plane/worker nodes).
If you have deployed TKG into a public cloud, then you can use the following types instead, and continue to follow this article as the theory is the same regardless of where you have deployed to:
AWSMachineTemplateon Amazon EC2AzureMachineTemplateon Azure
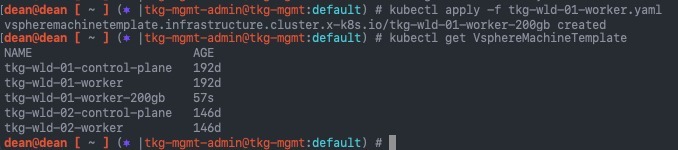
kubectl get VsphereMachineTemplate

You can attempt to directly alter this file, however, when trying to save the edited file, you will be presented with the following error message:
kubectl edit VsphereMachineTemplate tkg-wld-01-worker error: vspheremachinetemplates.infrastructure.cluster.x-k8s.io "tkg-wld-01-worker" could not be patched: admission webhook "validation.vspheremachinetemplate.infrastructure.x-k8s.io" denied the request: spec: Forbidden: VSphereMachineTemplateSpec is immutable

Instead, you must output the configuration to a local file and edit it. Also, you will need to remove the following fields if you are using my below method.
- Metadata
- kubectl.kubernetes.io/last-applied-configuration
- Remove all managed fields
- uid
- Ensure you don't remove the "ownerReferences"
- resourceVersion
Then provide a new Metadata Name.
kubectl get VsphereMachineTemplate tkg-wld-01-worker -o yaml > tkg-wld-01-worker.yaml
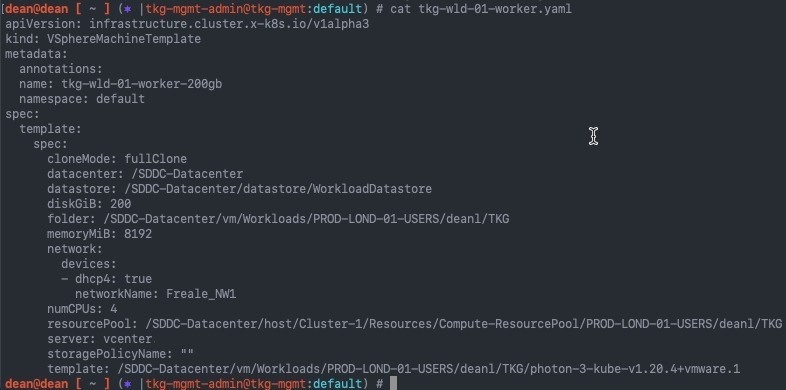
Here is an example of my edited VsphereMachineTemplate, where I have changed the default disk size to 200GB, to allow for more ephemeral disk space for containers:
Apply the new configuration.
kubectl apply -f tkg-wld-01-worker.yaml
Now, we need to update the "MachineDeployment" resource to use this new VsphereMachineTemplate, so that we can deploy new worker (compute plane) nodes with our newer configuration.
kubectl get MachineDeployment
kubectl edit MachineDeployment {Name}
What is a MachineDeployment? A MachineDeployment provides declarative updates for Machines and MachineSets. A MachineDeployment works similarly to a core Kubernetes Deployment. A MachineDeployment reconciles changes to a Machine spec by rolling out changes to 2 MachineSets, the old and the newly updated.

Below you can see I have changed the line "name" within the Template Spec to my new VsphereMachineTemplate name.
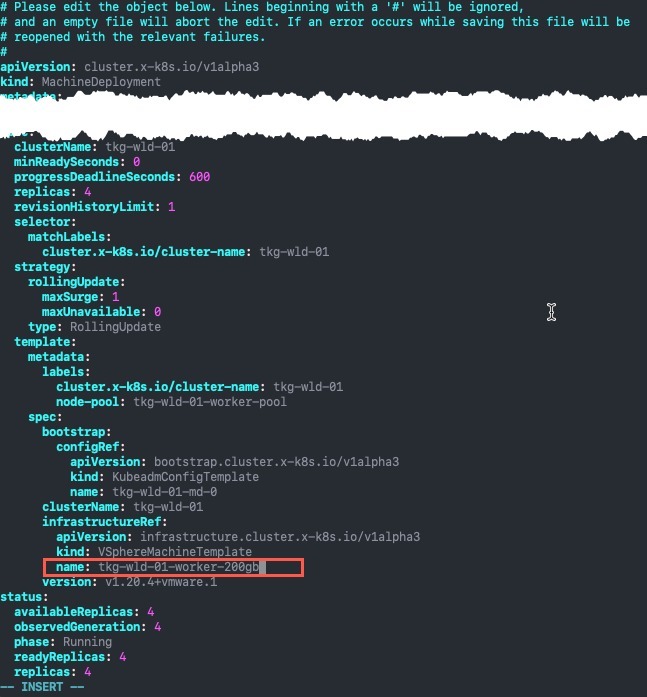
Below you can now see the status change to "updated" and that one node is "Unavailable" as the system starts to replace the nodes.

Once this change is made to the MachineDeployment, it will create a new MachineSet which uses the VsphereMachineTemplate and update the nodes in the cluster as per it's replacement policy configuration.
The original MachineSet will remain, you can clean this up manually.
What is a MachineSet? A MachineSet’s purpose is to maintain a stable set of Machines running at any given time. A MachineSet works similarly to a core Kubernetes ReplicaSet. MachineSets are not meant to be used directly, but are the mechanism MachineDeployments use to reconcile desired state.
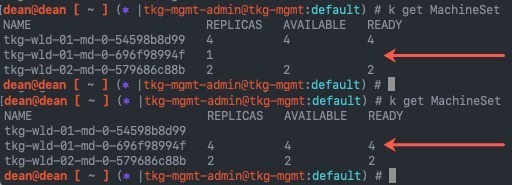
If change the context back to your Workload cluster, and run the below command, I can now see all the new worker nodes that have been created with a short age time. (Example picture shows before and after).
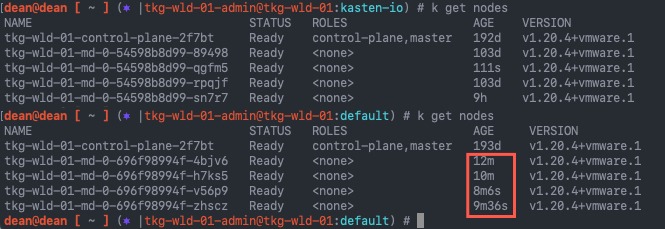
kubectl get nodes
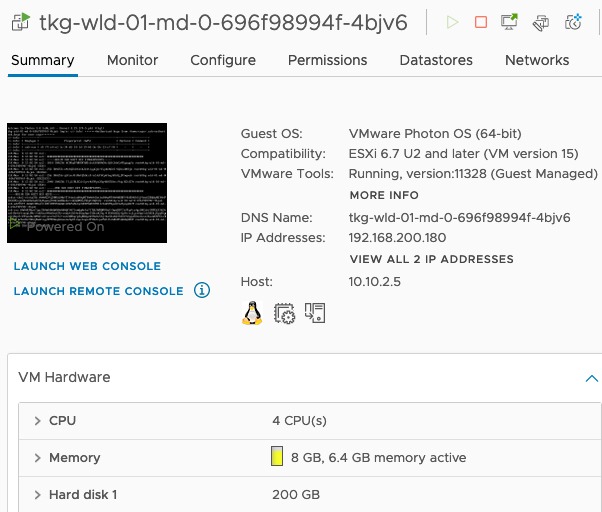
In vCenter, I can see that my new nodes have the larger disk size.
Final note, if you had any nodes in a cordon/drain state, then these will not have been replaced during the MachineDeployment reconciliation. You may need to remove and clean these objects up manually.
Resources
- VMware Documentation - Scale Tanzu Kubernetes Clusters
- Updating Machine Infrastructure and Bootstrap Templates
Regards