The Issue
Note: VMware has released a full in-depth KB Article that I'd advise you review along with this blog post. If you have any queries or concerns with the processes detailed, always open a support ticket! - How to rotate certificates in a Tanzu Kubernetes Grid cluster (86251)
One day my Kubernetes cluster just stopped responding. I could no longer connect to the Kubernetes API.
I rebooted all the nodes (as it was a demo environment) to no luck, and still nothing. So I had to go off digging.
The Cause
I SSH'd into one of my control-plane nodes, and started to tail the kubelet logs.
- Official Docs - Connect to Cluster Nodes with SSH
May 03 19:23:04 tkg-wld-01-control-plane-2f7bt kubelet[665]: E0503 19:23:04.984454 665 pod_workers.go:191] Error syncing pod 0e7fcb4098684424f3fe80747a0092dc ("kube-apiserver-tkg-wld-01-con
trol-plane-2f7bt_kube-system(0e7fcb4098684424f3fe80747a0092dc)"), skipping: failed to "StartContainer" for "kube-apiserver" with CrashLoopBackOff: "back-off 5m0s restarting failed container=kub
e-apiserver pod=kube-apiserver-tkg-wld-01-control-plane-2f7bt_kube-system(0e7fcb4098684424f3fe80747a0092dc)"
May 03 19:23:04 tkg-wld-01-control-plane-2f7bt kubelet[665]: I0503 19:23:04.983817 665 scope.go:111] [topologymanager] RemoveContainer - Container ID: e0e91eef758fff16f9bd0fbbb17fbc5c606468
70cb6ae774437f6f1d85cb3443
May 03 19:23:05 tkg-wld-01-control-plane-2f7bt kubelet[665]: E0503 19:23:05.514950 665 kubelet.go:2264] nodes have not yet been read at least once, cannot construct node object
May 03 19:23:05 tkg-wld-01-control-plane-2f7bt kubelet[665]: I0503 19:23:05.028683 665 kubelet.go:449] kubelet nodes not sync
May 03 19:23:04 tkg-wld-01-control-plane-2f7bt kubelet[665]: E0503 19:23:04.984454 665 pod_workers.go:191] Error syncing pod 0e7fcb4098684424f3fe80747a0092dc ("kube-apiserver-tkg-wld-01-con
trol-plane-2f7bt_kube-system(0e7fcb4098684424f3fe80747a0092dc)"), skipping: failed to "StartContainer" for "kube-apiserver" with CrashLoopBackOff: "back-off 5m0s restarting failed container=kub
e-apiserver pod=kube-apiserver-tkg-wld-01-control-plane-2f7bt_kube-system(0e7fcb4098684424f3fe80747a0092dc)"
May 03 19:23:04 tkg-wld-01-control-plane-2f7bt kubelet[665]: I0503 19:23:04.983817 665 scope.go:111] [topologymanager] RemoveContainer - Container ID: e0e91eef758fff16f9bd0fbbb17fbc5c606468
70cb6ae774437f6f1d85cb3443
May 03 19:23:01 tkg-wld-01-control-plane-2f7bt kubelet[665]: E0503 19:23:01.621724 665 controller.go:144] failed to ensure lease exists, will retry in 7s, error: Get "https://192.168.200.44
:6443/apis/coordination.k8s.io/v1/namespaces/kube-node-lease/leases/tkg-wld-01-control-plane-2f7bt?timeout=10s": dial tcp 192.168.200.44:6443: connect: no route to host
May 03 19:23:01 tkg-wld-01-control-plane-2f7bt kubelet[665]: E0503 19:23:01.621723 665 kubelet_node_status.go:93] Unable to register node "tkg-wld-01-control-plane-2f7bt" with API server: P
ost "https://192.168.200.44:6443/api/v1/nodes": dial tcp 192.168.200.44:6443: connect: no route to host
Next to get to the root of the issue, I looked at the ETCD container.
cat /var/log/containers/etcd-tkg-wld-01-control-plane-2f7bt_kube-system_etcd-3d1f904c86a23fc9d758b731492442fb0e522476c5e6eb7f1a222224a4cb6363.log
In the logs I could see the error clear as day. The self-signed certificate had expired.
embed: rejected connection from "127.0.0.1:47638" (error "tls: failed to verify client certificate: x509: certificate has expired or is not yet valid: current time 2022-05-03T18:17:34Z is after 2022-04-29T12:54:24Z",
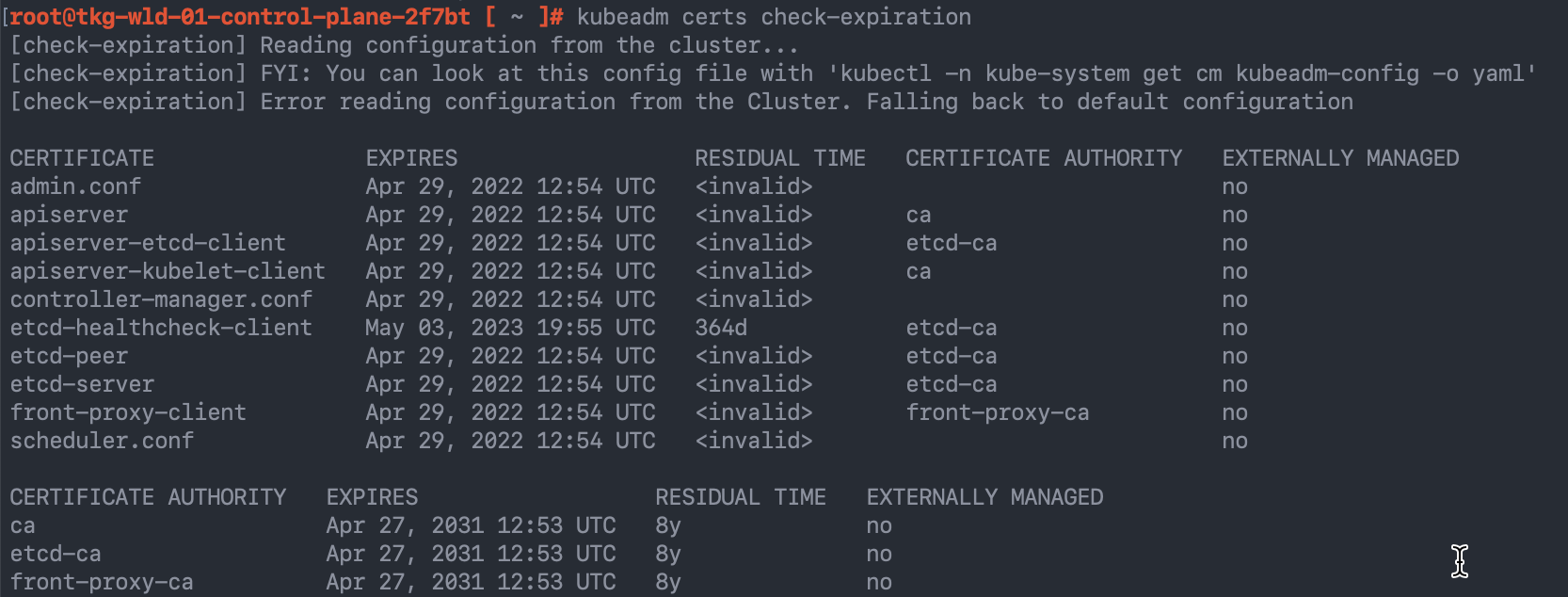
And then we an also confirm this by using the kubeadm command from the node as well.
root@tkg-wld-01-control-plane-2f7bt [ ~ ]# kubeadm certs check-expiration [check-expiration] Reading configuration from the cluster... [check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [check-expiration] Error reading configuration from the Cluster. Falling back to default configuration CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED admin.conf Apr 29, 2022 12:54 UTC <invalid> no apiserver Apr 29, 2022 12:54 UTC <invalid> ca no apiserver-etcd-client Apr 29, 2022 12:54 UTC <invalid> etcd-ca no apiserver-kubelet-client Apr 29, 2022 12:54 UTC <invalid> ca no controller-manager.conf Apr 29, 2022 12:54 UTC <invalid> no etcd-healthcheck-client May 03, 2023 19:55 UTC 364d etcd-ca no etcd-peer Apr 29, 2022 12:54 UTC <invalid> etcd-ca no etcd-server Apr 29, 2022 12:54 UTC <invalid> etcd-ca no front-proxy-client Apr 29, 2022 12:54 UTC <invalid> front-proxy-ca no scheduler.conf Apr 29, 2022 12:54 UTC <invalid> no CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED ca Apr 27, 2031 12:53 UTC 8y no etcd-ca Apr 27, 2031 12:53 UTC 8y no front-proxy-ca Apr 27, 2031 12:53 UTC 8y no
The Fix
First a quick note on why this fix isn't officially supported.
IMPORTANT: Management clusters and Tanzu Kubernetes clusters use client certificates to authenticate clients. These certificates are valid for one year. To renew them, upgrade your clusters at least once a year. (Source)
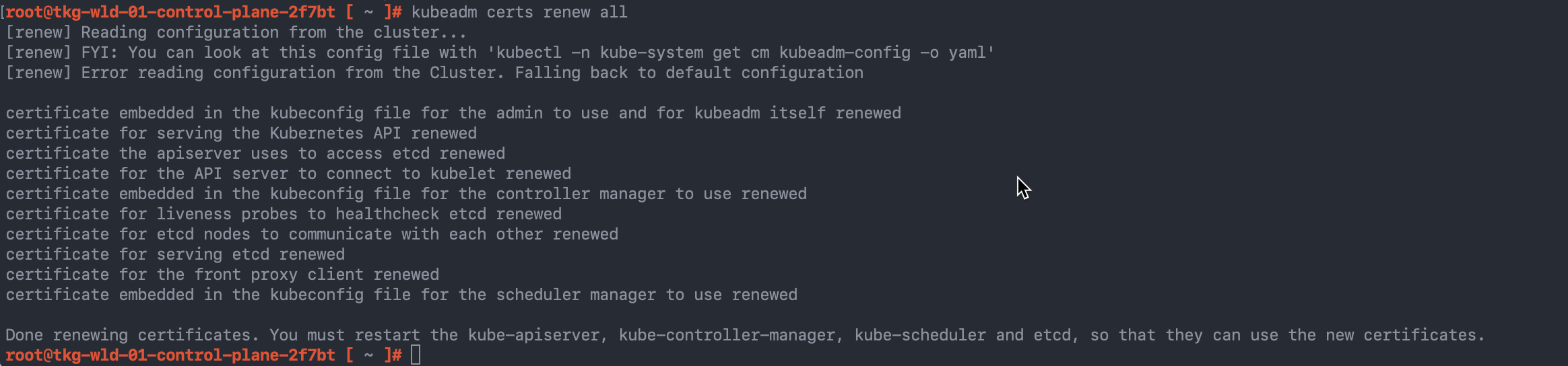
Now on to the actual fix, it's a simple one, just run the command "kubeadm certs renew all" and this will generate new certificates. You can specify individual certs to be renewed as needed.
Once you have done this, you need to restart the following services:
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- etcd
root@tkg-wld-01-control-plane-2f7bt [ ~ ]# kubeadm certs renew all [renew] Reading configuration from the cluster... [renew] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [renew] Error reading configuration from the Cluster. Falling back to default configuration certificate embedded in the kubeconfig file for the admin to use and for kubeadm itself renewed certificate for serving the Kubernetes API renewed certificate the apiserver uses to access etcd renewed certificate for the API server to connect to kubelet renewed certificate embedded in the kubeconfig file for the controller manager to use renewed certificate for liveness probes to healthcheck etcd renewed certificate for etcd nodes to communicate with each other renewed certificate for serving etcd renewed certificate for the front proxy client renewed certificate embedded in the kubeconfig file for the scheduler manager to use renewed Done renewing certificates. You must restart the kube-apiserver, kube-controller-manager, kube-scheduler and etcd, so that they can use the new certificates.
To get an updated kubeconfig file to use to authenticate from your customer, the kube-admin file is found below:
cat /etc/kubernetes/admin.conf
Regards