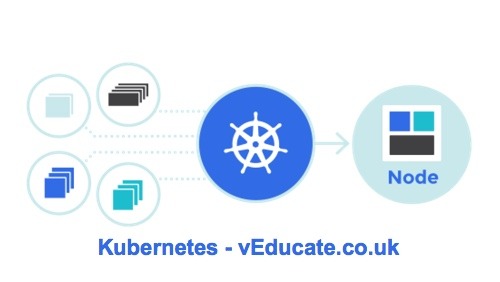
Kubernetes Troubleshooting - Kubelet Unable to attach or mount volumes - timed out waiting for the condition
The Issue When I updated my Kasten application in my Kubernetes cluster, I found that one of the pods was stuck in "init" status. dean@dean [ ~ ] (⎈…
Read guide →