This walk-through will detail the technical configurations for using vRA Code Stream to deploy Red Hat OpenShift Clusters, register them as Kubernetes endpoints in vRA Cloud Assembly and Code Stream, and finally register the newly created cluster in Tanzu Mission Control.
The deployment uses the Installer Provisioned Infrastructure method for deploying OpenShift to vSphere. Which means the installation tool "openshift-install" provisions the virtual machines and configures them for you, with the cluster using internal load balancing for it's API interfaces.
This post mirrors my original blog post on using vRA to deploy AWS EKS clusters.
Pre-reqs
- Red Hat Cloud Account
- With the ability to download and use a Pull Secret for creating OpenShift Clusters
- vRA access to create Code Stream Pipelines and associated objects inside the pipeline when it runs.
- Get CSP API access token for vRA Cloud or on-premises edition.
- Tanzu Mission Control access with ability to attach new clusters
- Get an CSP API access token for TMC
- vRA Code Stream configured with an available Docker Host that can connect to the network you will deploy the OpenShift clusters to.
- This Docker container is used for the pipeline
- You can find the Dockerfile here, and alter per your needs, including which versions of OpenShift you want to deploy.
- SSH Key for a bastion host access to your OpenShift nodes.
- vCenter account with appropriate permissions to deploy OpenShift
- You can use this PowerCLI script to create the role permissions.
- DNS records created for OpenShift Cluster
- api.{cluster_id}.{base_domain}
- *.apps.{cluster_id}.{base_domain}
- Files to create the pipeline are stored in either of these locations:
High Level Steps of this Pipeline
- Create an OpenShift Cluster
- Build a install-config.yaml file to be used by the OpenShift-Install command line tool
- Create cluster based on number of user provided inputs and vRA Variables
- Register OpenShift Cluster with vRA
- Create a service account on the cluster
- collect details of the cluster
- Register cluster as Kubernetes endpoint for Cloud Assembly and Code Stream using the vRA API
- Register OpenShift Cluster with Tanzu Mission Control
- Using the API
Creating a Code Stream Pipeline to deploy a OpenShift Cluster and register the endpoints with vRA and Tanzu Mission Control
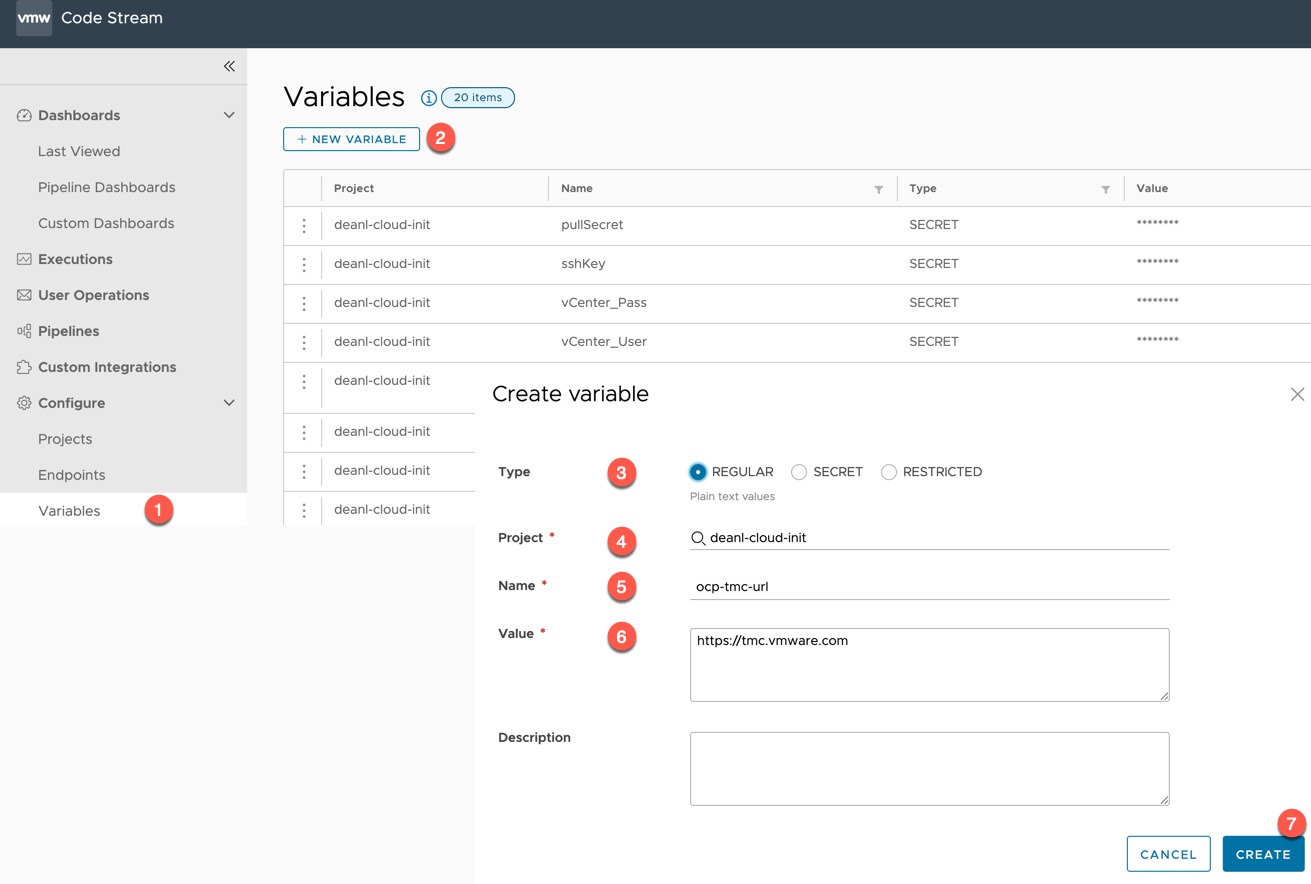
Create the variables to be used
First, we will create several variables in Code Stream, you could change the pipeline tasks to use inputs instead if you wanted.
- Create as regular variable
- ocp-tmc-url
- This is your Tanzu Mission Control URL
- ocp-tmc-url
- Create as secret
- ocp-tmc-token
- VMware Cloud Console token for access to use Tanzu Mission Control
- ocp-vra-token
- VMware Cloud Console token for access to use vRealize Automation Cloud
- vCenter_User
- Username of the vCenter you will be deploying the OpenShift Cluster to
- vCenter_Pass
- Password of the vCenter you will be deploying the OpenShift Cluster to
- pullSecret
- Red Hat OpenShift Pull Secret to enable the deployment of a cluster
- This needs to be encoded in Base64
- sshKey
- SSH Key file contents from a bastion node which should be able to SSH to the cluster nodes
- ocp-tmc-token
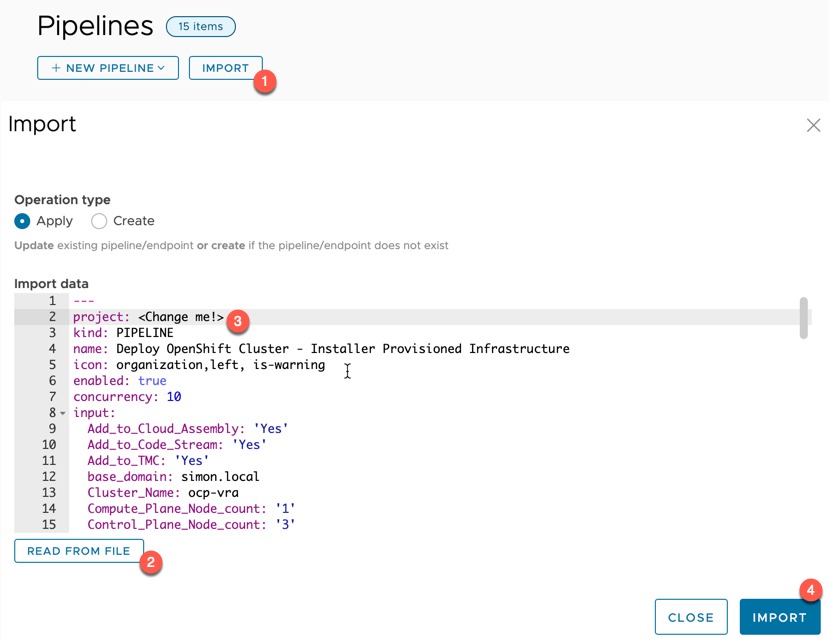
Import the "Deploy OpenShift Cluster - Installer Provisioned Infrastructure" pipeline
Create (import) the pipeline in Code Stream. (File here). Set line two to your project name then click import.
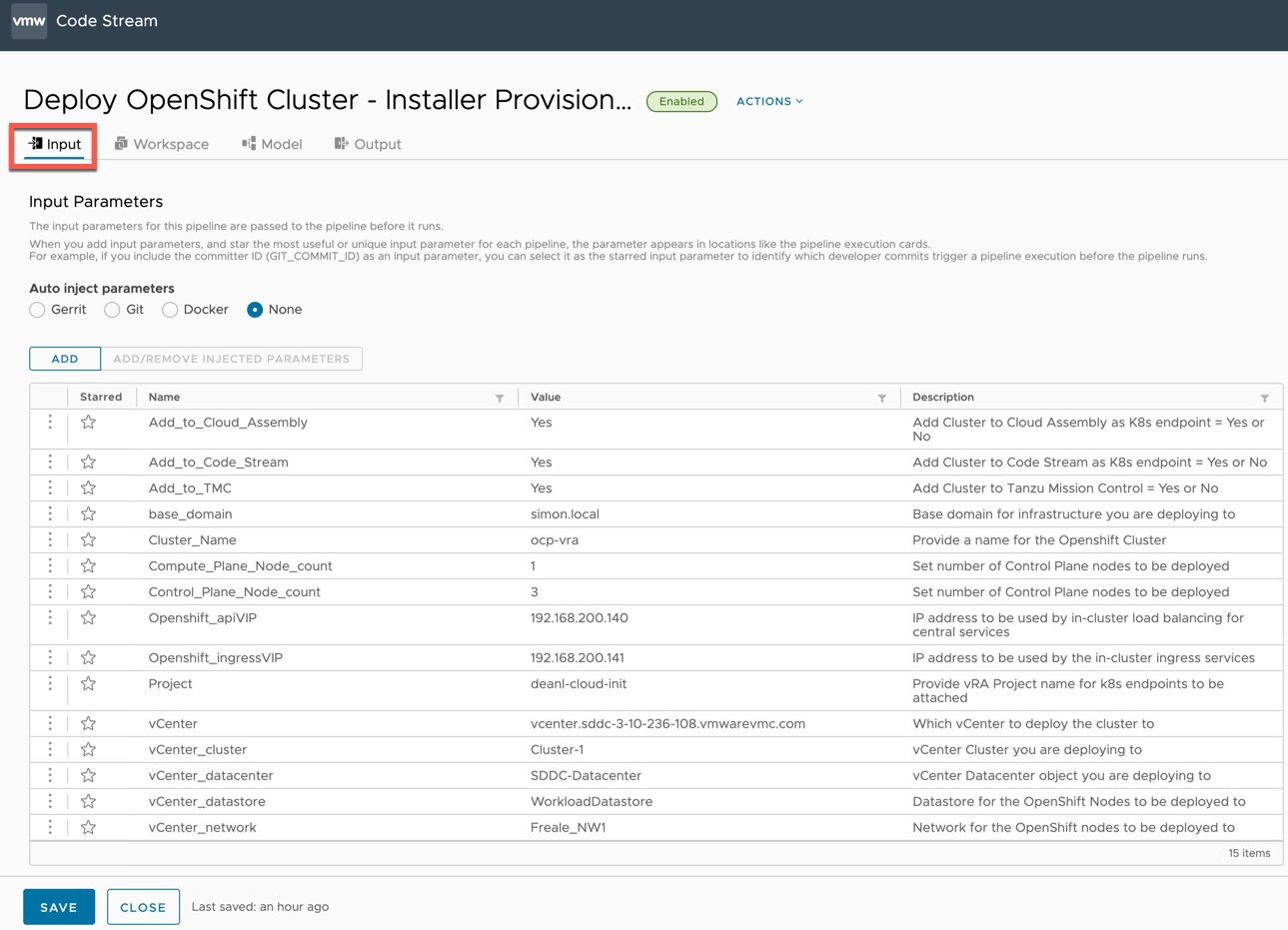
Open the pipeline, on the Input tab, change the defaults as necessary for your environment.
Set the Docker host to be used on the Workspace Tab.
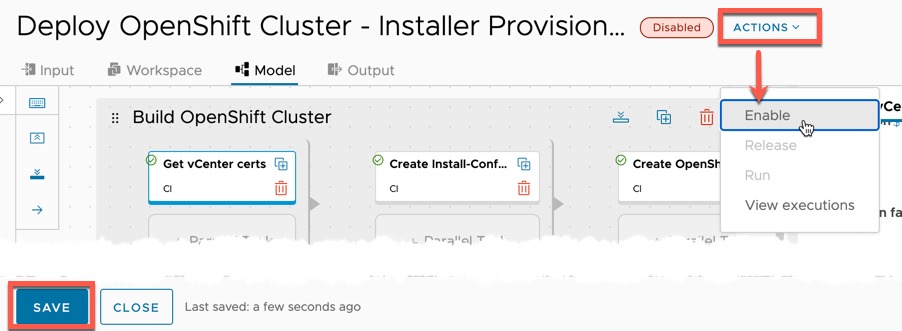
On the Model tab, it's worth clicking each task and validating, to ensure you get a green tick.
- If you get an error, resolve them. Usually, it's the referenced variable names do not match.

On the "Build OpenShift Cluster" stage, "Create OpenShift Cluster" task, there are several artifacts which will be saved to the Docker host.

You can also explore each of the tasks and make any changes you feel necessary. I wrote a blog post here on extracting files created by a CI Task and email notifications.
When you are happy, click save on the bottom left and enable the pipeline.
Running the pipeline
Now the pipeline is enabled, you will be able to run the pipeline.
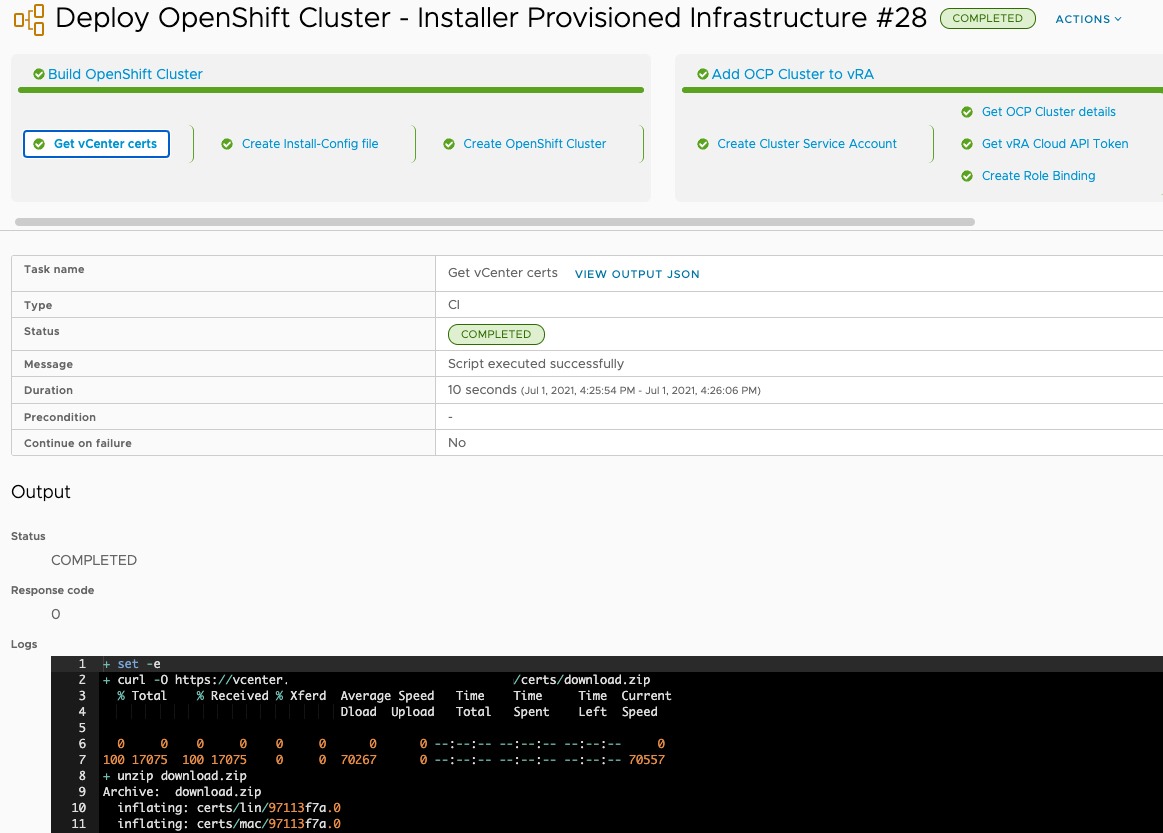
Click to view the running execution of the pipeline either on the Executions page, or from the little green dialog box that appears if you ran the pipeline from within the pipeline editing view.

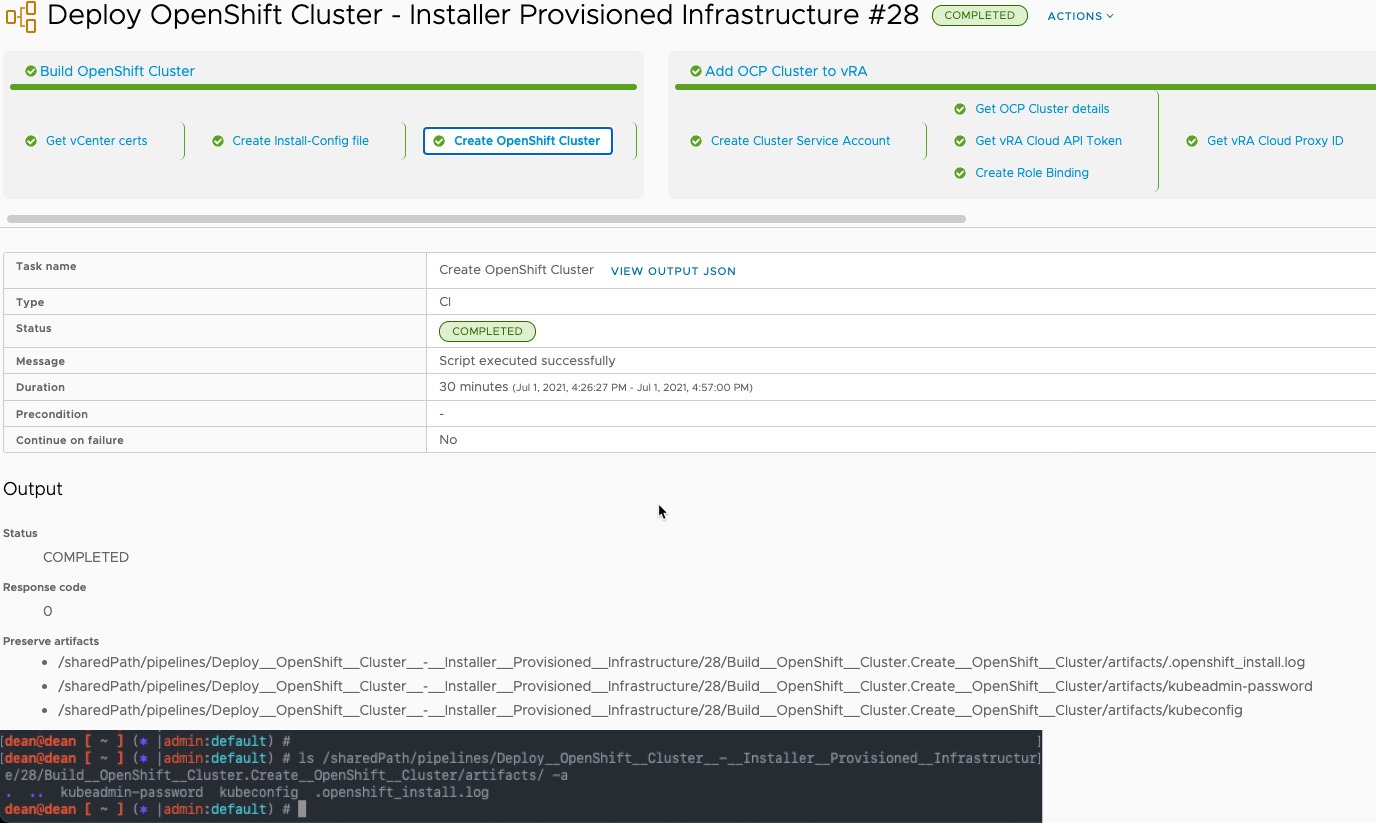
Below you can see the output of the first stage and task running. You can click each stage and task to see the progress and outputs from running the commands. Once the pipeline has completed, you'll see an output all green and the completed message.
Here is an example of the output files being preserved, with the locations on the docker host provided.
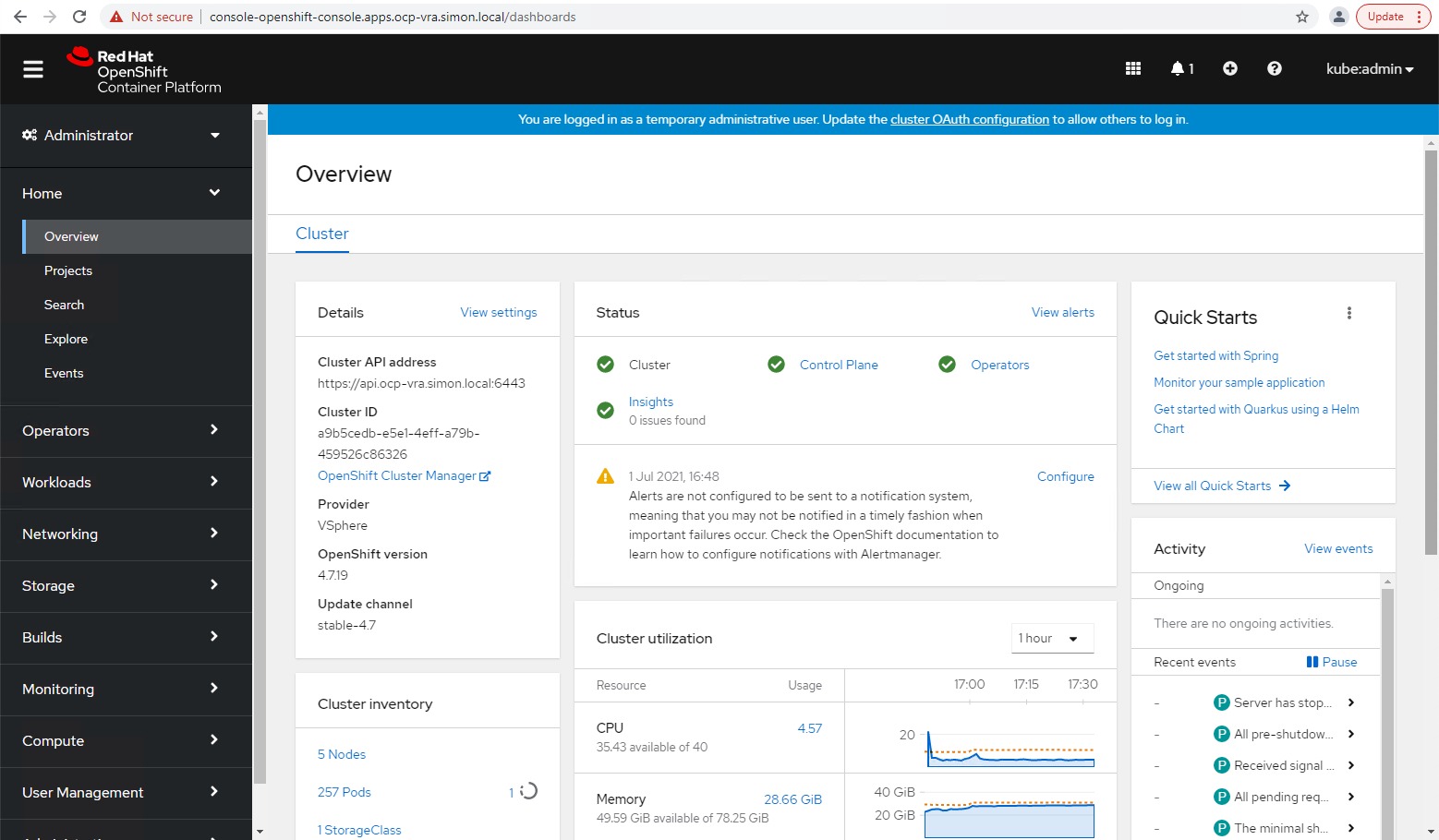
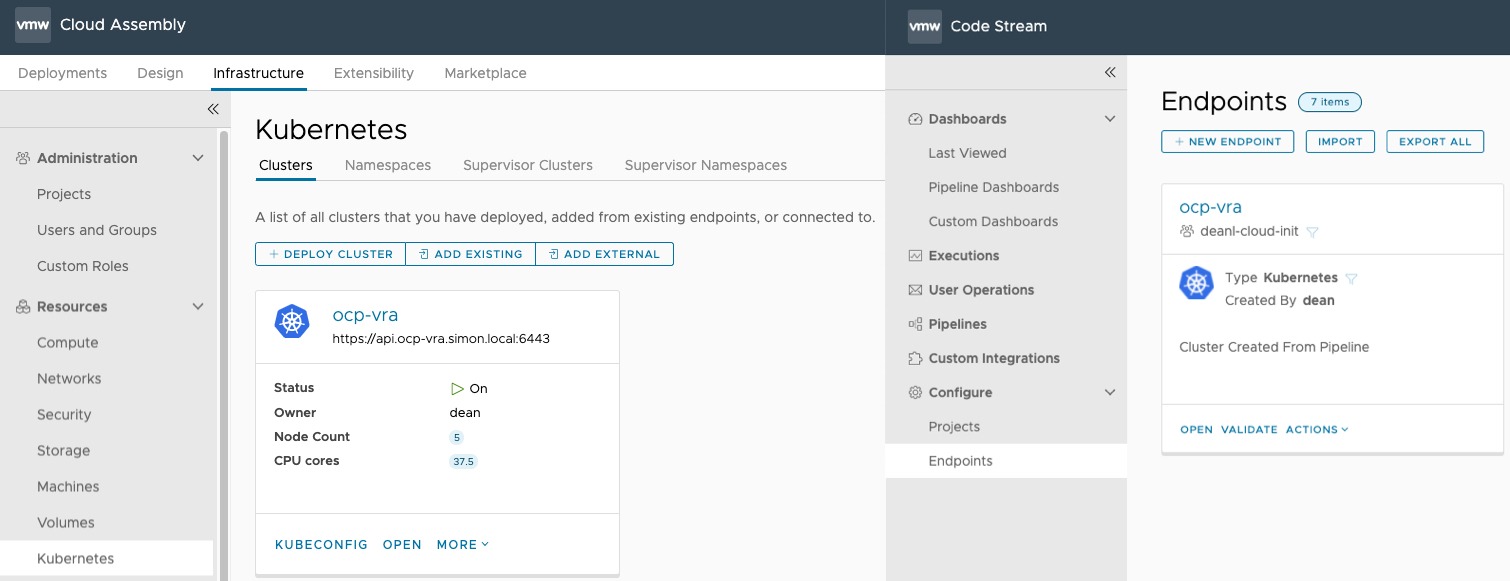
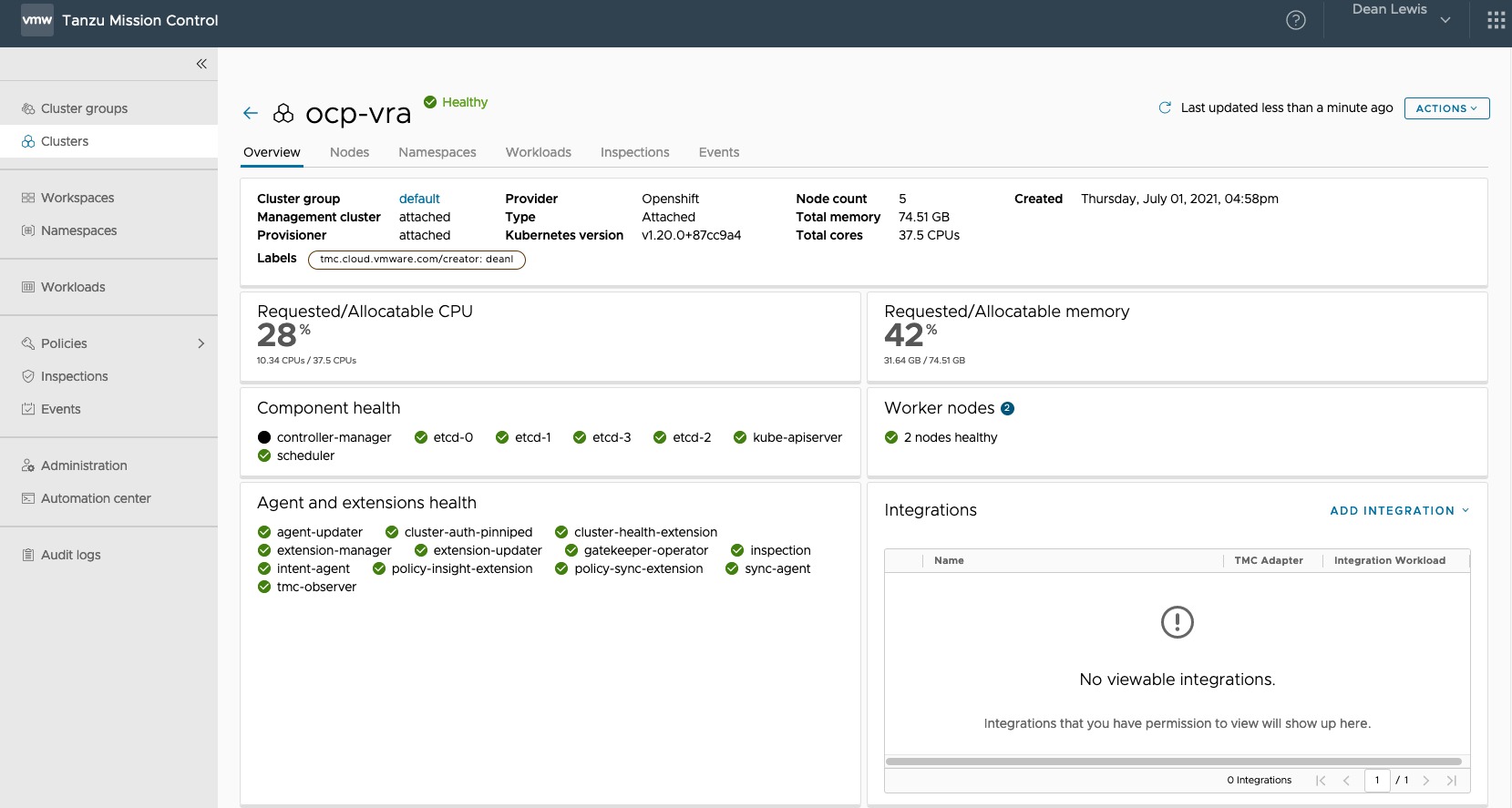
And finally, you'll have the following items created and configured.
- OpenShift Cluster
- Cloud Assembly - External Kubernetes Endpoint
- Code Stream - Kubernetes Endpoint
- Tanzu Mission Control - Kubernetes cluster attached
- Kubeconfig and KubeAdmin Password files available on the docker host as well as the OpenShift install log file (hidden attribute set). (Screenshot above).
- Want to have vRA email when these files are available and host them using a web server? See this link.
Wrap up
This blog post is built upon some of the configuration from my blog post deploying AWS EKS resources using vRA.
The main changes to make this solution work, is building a new container with the OpenShift CLI tools installed, and then building a YAML file which specifies how to deploy the OpenShift cluster.
Some other blogs that might be of use, especially if you are looking to alter this pipeline, or use OpenShift after deployment:
- How to specify your vSphere virtual machine resources when deploying Red Hat OpenShift
- Red Hat OpenShift on VMware vSphere – How to Scale and Edit your cluster deployments
- How to Install and configure vSphere CSI Driver on OpenShift 4.x
- vRealize Operations – Monitoring OpenShift Container Platform environments
- How to configure Red Hat OpenShift to forward logs to VMware vRealize Log Insight Cloud
- How to install and configure Kasten to protect container workloads on Red Hat OpenShift and VMware vSphere
- Enabling Tanzu Mission Control Data Protection on Red Hat OpenShift
Hopefully this was helpful.
Regards
I'm trying this out, but It fails on the second step of the Build Openshift Cluster workflow. The error doesn't tell me much either.
On "Create Intall-Config file" I get:
Build OpenShift Cluster.Create Install-Config file: com.google.gson.stream.MalformedJsonException: Unterminated array at line 1 column 52 path $[3]
Well, I didn't realize the base64 decode on the RH Pass variable. I've encoded the variable with bas64 and now it can process it fine.
It now fails, with issues regarding the install_config.yaml, but I don't see anything wrong with it. I've updated the installer to 4.8.4 (modified the dockerfile just to be sure it was the latest version). But it fails parsing the yaml with:
level=fatal msg=failed to fetch Metadata: failed to load asset "Install Config": failed to unmarshal install-config.yaml: error unmarshaling JSON: while decoding JSON: json: cannot unmarshal object into Go struct field InstallConfig.pullSecret of type string
I don't have any idea why. It looks exactly identical to the yaml I've created manually, and it works...
If any of the data is JSON format inside the YAML file (install-config.yaml) then when you run the pipeline, the JSON will get malformed.
Basically to get around this, I base64 encoded any JSON I had to pass through, such as the pullSecret, then set it as a variable in one of the CI Tasks, then created the YAML using the variable. Such as on the "Create install-config" task:
export pullSecret=$(echo ${var.pullSecret} | base64 -d)cat << EOF > install-config.yamlapiVersion: v1
>>>>redacting to shorten<<<< pullSecret: '$pullSecret' sshKey: '${var.sshKey}' EOF
It seems like something is not correct when building your install-config.yaml file for the formatting. I've just updated my container for the newer versions of Openshift-Install. And then run one of my previously successful pipelines. And this has build the cluster correctly.
You should look at the YAML file that's available under preserved artifacts.
Hi I see in your other comment you found the fix. I did detail this issue here as I had the same issue when I first built this pipeline:
http://82.68.36.172/vra-code-stream-json-malformed/
Hey Dean,
I've been trying to replicate this but I'm running into an issue with the network. The Create OpenShift Cluster step in the pipeline fails because it cannot find the NSX backed network but I'm unable to change the network type. Hope you can shed some light on this step of the pipeline.
If you run through the wizard manually, does the network appear as only a single item? and can it be selected? I've seen cases where by the network has been migrated as part of a NSX update or move from DVS, but templates etc still use the old network reference, therefore it shows up under the network inventory view in vCenter, even though it's not actually available for us. This means it's discovered by OpenShift and can be selected in error.
I noticed you made this comment a while ago, so if you've since resolved it, let me know how! :)