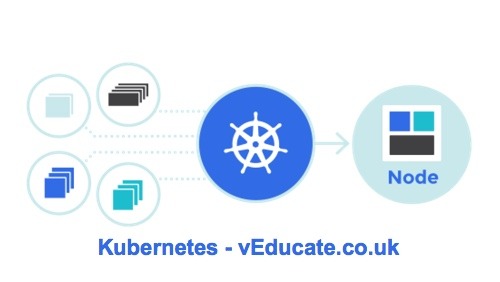
Tanzu Kubernetes Grid 1.6 - Management Cluster deployment failure - unable to patch the cluster object
The Issue When deploying a brand new Tanzu Kubernete Grid Management Cluster to a vSphere environment we kept hitting failures like the below. The deployment…
Read guide →